
Introduction
I participated briefly in the Advent of Code 2018. Every year, they post 31 coding puzzles, 2 per day. You have to solve them before you can proceed to next one. I wanted to post about what I learned. I’ve never participated before, and wanted to use it an excuse to force myself to use a Functional Programming language. I use Functional Programming concepts in my day job, but never had the opportunity to immerse myself, and force myself, to accomplish harder challenges in a pure FP language. It was doubly hard because the exercises are NOT what I do at my day job at all and are challenging. They were very hard in a fun way, though. Below I’ll cover the 6 exercises I did (I threw in the towel on Day 7), and explain some of the interesting nuances I found either with the exercise and thinking in FP… and thinking in Elm.
Why Elm?
Elm is a Functional Programming language for building web applications. It’s like Haskell, but has little to no Category Theory nonsense, and is sort of tailored for traditional UI/web developers. Given I’d been away from front-end development for awhile dealing with Python, Node, and Go for the past 2 years, I figured Elm was a great choice to get back into front-end. I had struggles in the past with Elm, especially around random numbers, and the figuring out what the compilation type errors meant.
Overall Challenges With Elm
I had a few challenges with the Elm language I’d like to highlight that I found interesting. I’ve played with Elm a couple of times in the past, and while time away learning more FP did help a lot, I still had struggles.
Out of Practice with Types
When I thought TypeScript was cool, the rest of the JavaScript industry did not, so I learned to live without types for a long time. I came from ActionScript 2 and 3 which are like Java, so I had spent years getting comfortable and happy with types. Getting into JavaScript, the industry wasn’t ready for them, so I learned to go without.
Going back is super rough after spending years in JavaScript, Lua, Python, and even a brief stint in Go. Trying to do currying in Go was an exercise in pure masochism whereas it is built in in Elm and falls in the background, almost unnoticed. I think in 6 exercises I used 1 partial application without composing (which in Elm doesn’t really count).
My main challenge though with the types is playing with ideas now has another, huge cost. I only care if the code mostly works; I’m just trying to validate some ideas and approaches. Elm, and the Hindley-Milner type system specifically, help ensure no runtime errors which means they pull no punches with letting you know how your code is “incorrect”. There is no any like there is in TypeScript. While this is great for production code, it’s awful for when you “have a day to vet a solution(s) and come up with a mostly working prototype”.
Time and time again I would break out JavaScript and Node either locally or in Code Sandbox IO to play with ideas and test algorithms, THEN I’d rewrite in Elm. Starting in Elm was harder for some algorithms I couldn’t wrap my head around just yet.
No Loops, Only Recursion
Elm being purely functional means there are no loops for programming. You can only use recursion to ensure no side effects. Given a lot of the Advent of Code 2018 exercises were around parsing large arrays/lists multiple times, it was very common to see JavaScript and Python solutions use while(true) with a break when some condition was met and nested for loops often.
Elm has no loops. Instead, you either use manual recursion where a function calls itself, or a case statement (which is not a JavaScript switch statement and more like an Elixir pattern matching case). I’ll cover a few examples below. I point this out because that way of thinking is SUPER HARD after 15+ years of my brain being wired to think in loops and nested loops. You do a lot of that in GUI programming for layout and it’s amazing how hard it was for even simple things to think recursively.
Syntax Whitespace
Elm is almost as strict about whitespace as Python. I say almost because it’s still unclear when a return statement will completely break compilation or it’s fine and suddenly things are much more readable. I failed to find a good guide on what you’re allowed do and suggestions beyond commas before items in lists.
I bring this up because…
Verbose Anonymous Functions
… anonymous functions are a bit verbose. You NEED them when you’re playing with ideas, especially when you’re porting from Python or JavaScript. I don’t just mean the ideas, I also mean the types specifically. You may like your chain of parsing code… but aren’t sure yet if you’re going to commit to a List or an Array, nor do you know what types will be in that list yet. Anon functions allow a lot of flexibility in Elm combined with let statements to log things out before you’re ready to commit to types and more normal, non-anonymous functions.
Now, the syntax itself is nice: (\arg -> arg + 1)
Compare that with JavaScript: arg => arg + 1
However, once you start whipping out the foldl (Elm’s version of Array.reduce) function, things can get pretty gnarly to read pretty quickly. I never figured out a good spacing solution/convention here beyond “refactor it to normal functions so you can actually read it”. I’ll show some examples below of smushed anons and you’ll go “Oh… gross, refactor that, man!”
Approaching Full Lisp with Tons of Parenthesis
Applying FP concepts in JavaScript has resulted in my JavaScript looking a lot like Lisp in the annoying way: tons of parenthesis because of curried functions everywhere.
.then( value => something(JSON)(request)(value) )Code language: JavaScript (javascript)Even when I took out anonymous functions, I still had nested functions, and sometimes Elm doesn’t know what you mean so you have to use parenthesis to tell it exactly. Still, it’s MUUUUCH more preferable to have to add them later vs. being required like you are in JavaScript/Python FP programming.
Here, we have a large chained set of functions and the parenthesis aren’t bad at all:
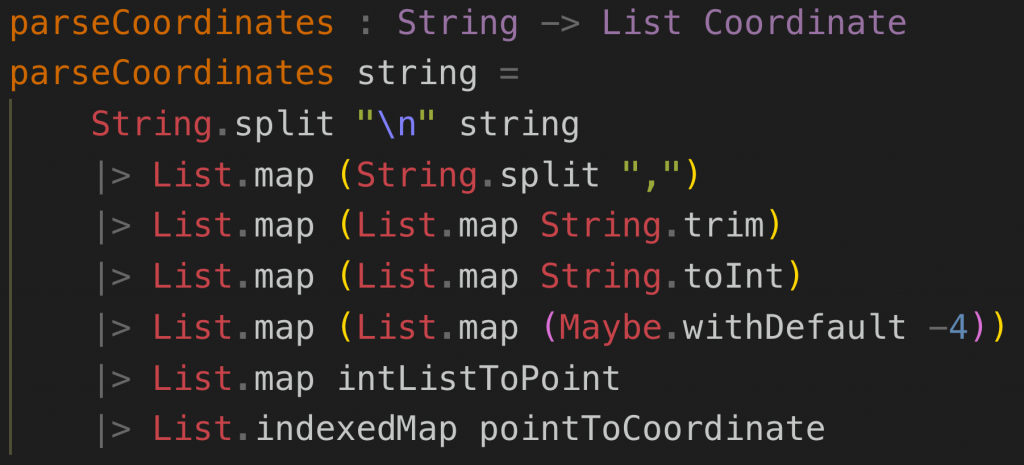
Yet here, I’m just creating a simple type with parameters… but I have functions to ensure they are converted and… bleh:

Again, much better than JavaScript, I realize this is super nitpicking.
Tooling Coloring
I’ve always thrived on code coloring; it helps me quickly see the different parts of the code and help me comprehend what a function is doing. My current Elm plugin for VSCode however doesn’t seem to highlight methods correctly, only the modules. This becomes a problem when you import both Array and List and they have many of the same method names like map. To ensure you don’t get a compilation error, it’s just easier to prefix the method with the module, which you start doing with unrelated things like Maybe just to be consistent. You make your code more verbose, though.
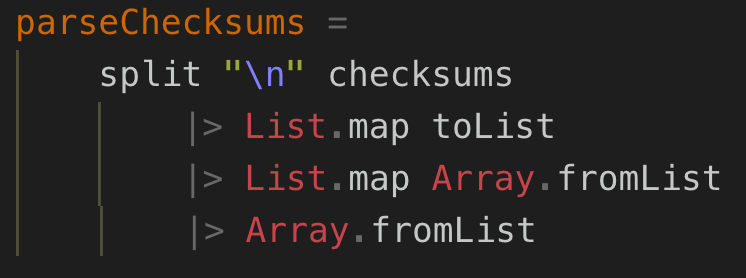
Notice how none of the methods, both mine and the native ones, are colored; the same gray color. It stays that way if you omit List and Array resulting in this:

Terse, yes, readable… sure, but I want my colors like I have with all the good Python and JavaScript code coloring plugins. It’d also get confused about exactly where the error is in the code when clicking the errors in the compilation/errors area and scroll to the wrong part. Still, I liked the red underline of problem areas + on the right side indicating where in the code issues were.
Modern Web Compilation Toolchain
In JavaScript, you can actually devote your entire career to D3.js, making data visualizations. The same can be said for compiling JavaScript using Babel and Webpack together. For those of us who came from a world where companies build all that for you such as C, Visual Studio Code for C#, ActionScript in Flash/Flash Builder Eclipse and nowadays Create React App, Angular CLI, and Vue CLI… it’s ridiculous to think all of us are interested in, yet again, creating a custom compilation chain for Elm in the browser. For must of us, we have the same common need: convert this Elm to JS and put in an index.html.
Elm Reactor never seems to work for me, and while you can survive for a little while using just a Main.elm file, eventually you’ll need a basic index.html… like… you know, every other web app today. I prefer Facebook to create, upgrade, and maintain my compilation toolchain (create react app) while I focus on building things. Elm doesn’t have that yet (or I just suck at Elm Reactor) so I hacked the minimal Webpack required possible and just copy pasta’d between projects. I bring this up because the big 3 realized awhile ago you need a cli to do this stuff for developers and it’s a huge time sink + duplicated effort without. Playing the waiting game has some benefits such at ES6 ALMOST works in modern browsers, heh, but… for those of us who want to code and deploy today… we need better.
Type Hinting is “Ok”
Considering we’re using one of the best in class type systems, shouldn’t the type hints I receive when using a function or module also be best in class? Apparently not. Observe me trying to use a previously defined function and a type; both give me pathetic code hints. I’ve seen it sometimes work; maybe I should be using some other extension or something other than VSCode.
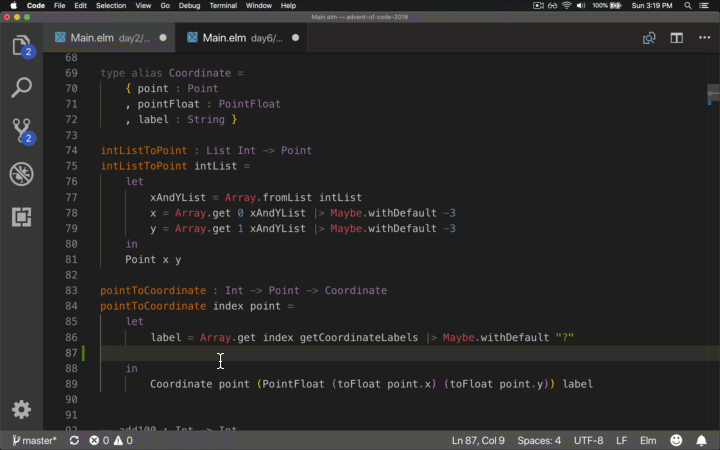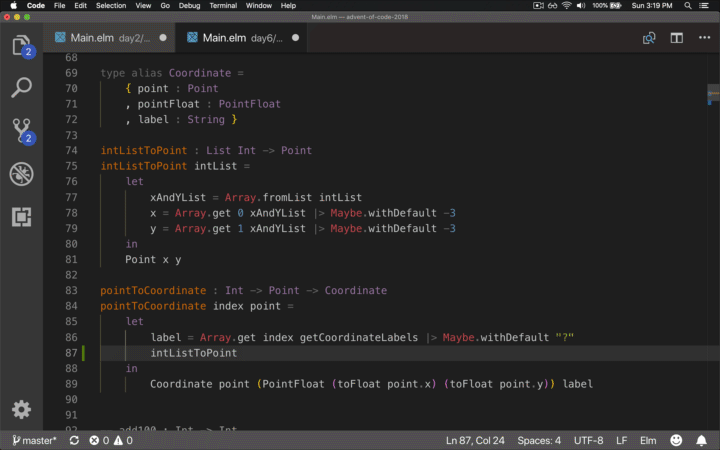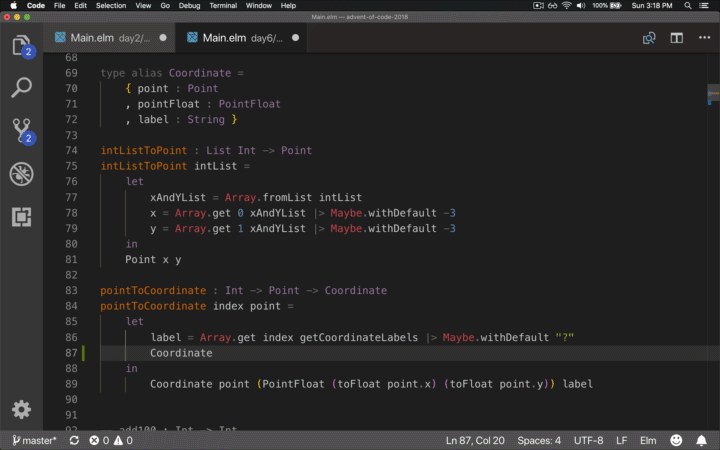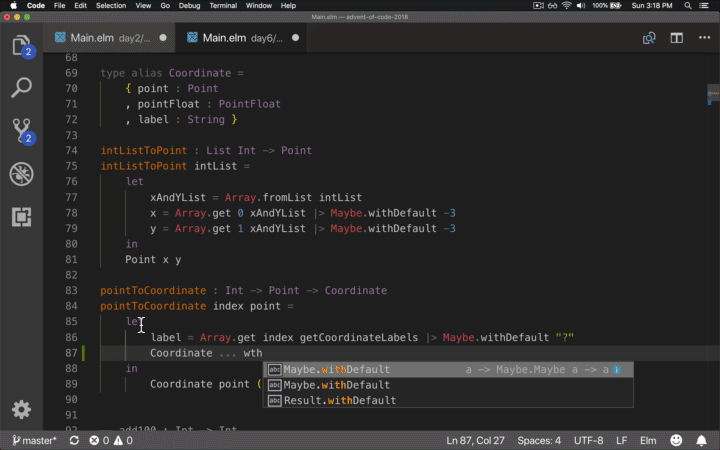
Concurrency
Many of the exercises are meant to get the performance nerds excited. As a FP programmer in dynamic languages, the last thing I care about is performance… because it’s not a problem I have. I’m building web applications to show 20 items in a table, or pulling 12kb of JSON from a Lambda web service. However, even some of the basic exercises would get you to tens of thousands to hundreds of thousands of iterations. I heard from my friends who were much farther along they were well into the millions and wondering how their Python would compare against the likes of Go and Rust for some of the exercises.
I noticed that the UI would get blocked for a lot of my code. Now, even the low hanging fruit of using a List over an Array, or a Set over an Array I could of made some big gains, but even the little things I ignored too. Perhaps it would help a lot, but above 10,000 iterations I highly doubt it. Since I was building UI’s for all my exercises and none of my loops needed I/O, this is a perfect use case for WebWorkers. Elm has a initial Process API, but the documentation makes it sound like it’s not ready yet. The only time the long running loops broke my browser were because I was logging so much JSON it made Chrome run out of memory. However, if I turned logs off, Days 1 – 6 ran in a reasonable amount of time. As a UI developer, I know blocking the UI is amateur hour given the API’s we have in the browser, so I’d like to figure out the correct way to do that in Elm.
Day 1 – 6 Review
Below I’ll cover the code for each exercise. While you can read the code to see how I solved the challenges on your own, I’m just covering the parts I thought were interesting about learning Elm and FP in general.
Elm uses extensive use of the pipeline operator; you can learn more about it if the use in the code below doesn’t make sense.
Day 1: Frequency Parser
Source Code | Link to Application
Day 1, Challenge 1 was pretty straightforward: parse a list of positive and negative integers. The solution is basically taking all those numbers and adding them up. This is the kind of stuff list comprehensions were built for:
frequency = List.sum listCode language: PHP (php)That’s about the same as sum in Lodash:
const frequency = sum(list)Code language: PHP (php)However, Challenge 2 you have to find when it reaches the same number twice. The easiest way in imperative coding is to simply use a while(true) and use a JavaScript Set to ensure no duplicates get added and just increment a counter. Yet, this is Elm, so it was my first taste of using recursion to solve a problem. It was also the first indication of a pattern: foldl is used for all the things. Seriously, since most of the challenges were looping through lots of items and changing them, you end up using foldl as your go to for everything.
This was also the first pattern of many where I gave up, whipped out JavaScript, then went back into Elm. The speed at which you can quickly prototype 1 line of code or 1 algorithm I cannot currently match in Elm, even in the elm repl. The Elm in browser editor Ellie App helps, no doubt, but it’s not as fast as Node or Python are on the command line.
It ended up being:
matchOrNot = reduceUntilMatch { matched = False, frequency = 0, match = 0, set = Set.singleton 0 } listCode language: PHP (php)Where reduceUntilMatch keeps calling itself until it finds a match. All reduce functions have an initial state, and that MatchOrNot type I create was basically a collection of the 4 variables I created in the JavaScript loop version, heh.
Day 2: Checksum Parser
Source Code | Link To Application
I don’t know much about checksums, but Day 2 was the only one I breezed through without having to think hard, debug for days, and/or whip out JavaScript or Python.
A few interesting things that started happening at this point in the exercises. First, I stopped caring about typing all my functions. The Elm compiler was good enough to infer what I needed and sometimes providing code hints in my code for me. Second, this then lead to more uses of anonymous functions.
filterOutSameLetters charList =
List.map (partitionSameLetters charList) charList
|> List.filter (\matchList -> List.length matchList > 1)Code language: PHP (php)Notice no type definition above filterOutSameLetters and I didn’t take the time to define the filter function.
Third, Maybes started to get annoying. Most type systems can’t type things in RAM like “what is item 3 in a List of Strings?” Instead they give you a Maybe value. However, once you start composing things, you can have start dealing with default values which can be a pain. You really really really have to think about the ramifications, both at the point you give a default value, and later down the line: what does this do to the correctness of my algorithm? I briefly had these problems in JavaScript, but I’m doing UI or API development, not Machine Learning/Data Science so I don’t deal with this level of data correctness in my job. Here in Elm, with types, it amplified.
Fourth, that really drove home I could have massive bugs in “code that compiles and has no runtime errors”. That was massive pill to swallow. I had gone down the FP path to create code that I kept hearing was better, more resilient, and had no errors. I had apparently missed the nuance around “no errors” still meaning you code could be “wrong” and “broken”, hah!
Finally, fifth, the let keyword is a godsend. I need to create imperative style code to play with my functions and algorithms in Elm. You write a variable, and then log it out a line below:
filteredMatches =
Array.filter (\item -> item.match == True) matches
filteredMatcheslog = log "filteredMatches" filteredMatchesCode language: PHP (php)In JavaScript, there is a trend hardcore FP’ers will ensure fat arrow functions don’t have squiggly braces {} because that implies the code is imperative and may hide side effects.
const doStuff = arg => someFunction(arg)Code language: JavaScript (javascript)However, as SOON AS something is weird, they’ll (myself included) change it back so they can debug what’s going on:
const doStuff = arg => {
console.log("arg:", arg)
const result = someFunction(arg)
console.log("result:", result)
return result
}Code language: JavaScript (javascript)I’m not sure why, but I felt a lot less guilty using let in Elm.
Day 3: Claims Parser
Source Code | Link To Application
I’ve seen it stated the main difference between a senior developer and a junior is that the senior, when they write a line of code, it will live longer than the junior’s. The junior will write it, modify it, then later delete it as part of a larger refactoring effort. Day 3 confirmed that I am indeed a junior in Elm. After spending 5 days, and finally figuring things out in Python and JavaScript, I rewrote my 4 days of work in Elm and started from scratch because the algorithms I had created were too hard to untangle. I haven’t felt that n00b in a long time which was kind of cool, yet humbling.
The exercise is to calculate where all rectangles are drawn, and then the overlap, and the largest overlap. I used Canvas to visualize since I feel at home there and liked to see my algorithms work or fail. That and most importantly, I’ve always dreamed what UI development would be without state, specifically drawing things. I don’t know how I’d do this in JavaScript, but in Elm it just feels super natural and not as alien as I thought.
Defining types in Elm is easy, but creating them has been challenging.
type alias Claim =
{ id : Int
, rectangle : Rectangle
, calculated : Bool
, overlaps : Bool }
type alias Rectangle =
{ left : Int
, top : Int
, width : Int
, height : Int
, right : Int
, bottom : Int
, overlaps : Bool }I started using helper functions to simply the creation and reduce how many parenthesis I had to use. Case in point, creating a Rectangle, and then creating a Claim which composes a Rectangle within it.
-- easier if I make a function so I can generate the right and bottom properties when you make the rectangle
getRectangle : Int -> Int -> Int -> Int -> Rectangle
getRectangle left top width height =
Rectangle left top width height (left + width) (top + height) False
-- easier to create a claim this way, less parameters
getClaim : Int -> Int -> Int -> Int -> Int -> Claim
getClaim id left top width height =
Claim id (getRectangle left top width height) False FalseCode language: JavaScript (javascript)Seems like boilerplate, but man, using it was as simple as:
getClaim id left top width heightSadly, I still had type cast the integers to floats when I went to draw them in the Canvas (note the toFloat ):
renderFilledRectangle x y width height color cmds =
cmds
|> Canvas.fillStyle color
|> Canvas.fillRect (toFloat x) (toFloat y) (toFloat width) (toFloat height)Which is ok. I started learning that most of the code had no care about floats; the only thing which consistently cared about that was the View so I made that a View problem to handle which makes my data code a lot easier to deal with. That and I don’t need high precision in the UI; we’re just visualizing things, not making important decisions based on a pixel’s location.
Finally, Day 3 is where the types in Elm really drive home why you can’t get runtime errors. The sheer amount of typing it took to parse the String JSON to an Elm type compared to zero effort on JavaScript’s part is night and day… like 1 line of JavaScript to 88 lines of Elm. In JavaScript, you just read the file via fs.readFileSync and then JSON.parse .
In Elm, however, JSON.parse is full of side effects, so they make you use lower-level primitives and you have to parse your way up. You can either parse raw Strings which I did in Day 3, or use their parser engine which I’ll talk about in another exercise below. Here’s parsing a single claim.
parseClaimStrings : Array String -> Claim
parseClaimStrings stringArray =
let
id =
Array.get 0 stringArray
|> Maybe.withDefault "#0"
|> String.replace "#" ""
|> String.toInt
|> Maybe.withDefault 0
left =
Array.get 2 stringArray
|> Maybe.withDefault ","
|> String.split ","
|> Array.fromList
|> Array.get 0
|> Maybe.withDefault "0"
|> String.toInt
|> Maybe.withDefault 0
top =
Array.get 2 stringArray
|> Maybe.withDefault ","
|> String.split ","
|> Array.fromList
|> Array.get 1
|> Maybe.withDefault "0"
|> String.replace ":" ""
|> String.toInt
|> Maybe.withDefault 0
width =
Array.get 3 stringArray
|> Maybe.withDefault "x"
|> String.split "x"
|> Array.fromList
|> Array.get 0
|> Maybe.withDefault "0"
|> String.toInt
|> Maybe.withDefault 0
height =
Array.get 3 stringArray
|> Maybe.withDefault "x"
|> String.split "x"
|> Array.fromList
|> Array.get 1
|> Maybe.withDefault "0"
|> String.toInt
|> Maybe.withDefault 0
in
getClaim id left top width heightCode language: JavaScript (javascript) I know that’s a bit insane, so let’s just take the width portion and do a side by side with JavaScript to see what we’re dealing with. In both languages, you have a string that looks like #147 @ 570,688: 27x25. That is a claim; an id number with an x and a y position divided by a comma, and finally a width and height divided by an x. For the width, we need that 570 number. For both Elm and JavaScript, if you split that on the space, you can pick out what you need from an Array by index. i.e. 0 will be the id, 2 will be x and y together, and 3 will be the width. That looks like 27x25. Parsing that with pure functions that cannot throw errors, let’s break down the algorithm:
width =
Array.get 3 stringArray
|> Maybe.withDefault "x"
|> String.split "x"
|> Array.fromList
|> Array.get 0
|> Maybe.withDefault "0"
|> String.toInt
|> Maybe.withDefault 0Code language: JavaScript (javascript)Array.get 3 stringArraygives you aMaybe; it’ll either beJust(27x25)orNothing- Because of the
Nothing, we say “ok, default with an ‘x’ then” so you can split and get nothing later down the line” usingMaybe.withDefault "x" String.split "x"will give us a List with 2 items. If it’s just “x”, well, it’ll be a List with 2 empty Strings… otherwise it’ll be["27", "25"]- However, you can’t get individual items in an
List(List has nogetmethod) so we have to convert to anArrayso we can get the first item, the width. (“Jesse, why didn’t you use List.head?” “Because I’m a n00b!”) - … however (again),
Array.get 0gives us aMaybe; eitherJust("27")orNothingso… we default to “0” knowing we’ll attempt to convert from a String to an integer later. -
String.toIntwill give you yet another bloodyMaybebecause there is no way to guarantee the String is parseable as an Integer using the types, so… we default to 0.
JavaScript? parseInt(str.split(' ')[3].split('x')[0]) although, a couple JavaScript and Python implementations I saw didn’t even parse it out; they just used those strings as lookups in an Object/Dictionary.
Now, the good news, that entire Elm pipeline is type safe. Meaning, I won’t get any exceptions at runtime no matter how bad the String is mangled. The bad news is you really need to think about the default values for the Maybes. What if 0 really is a valid value for example? I probably should have used Result instead to be more strict with the parsing. You can see, however, that assuming your data is static, how JavaScript is a lot more terse, and easier to play with ideas if you don’t care about types and generally know your data is ok.
One side note is that the Elm Canvas version 3 uses requestAnimationFrame for efficient rendering, but doesn’t work in Ellie App. Version 2 does work in Ellie App AND doesn’t require your Elm application to care about subscriptions (think WebSockets in Redux). So I stuck with v2. Despite the fact they both require a JavaScript pipe (the 2nd way I found to crash an Elm app by writing crappy JavaScript in a pipe), I never had any Canvas issues at all; wonderful library.
Day 4: Sleep Schedule
Source Code | Link To Application
Day 4 was about parsing sleep times. Like many a programmer, I dread anything dealing with Date math. Elm, unlike JavaScript, has only Posix time, and … well, the API sucks compared to JavaScript’s, especially with something like Moment or date-fns. There are a few Elm date libraries, but I found I could get by doing integer math myself.
I struggled to get the sorting right, so dropped into the Elm Slack where they had an Advent Of Code 2018 room to see how others were approaching it. I noticed one developer used a different type of String parsing I hand’t seen before part of the Parser library. It parses things string character by string character, but supports branching in case the strings don’t align up because of whitespace or some other reason. I used this as an opportunity to learn it vs. my traditional String to Array fu. The case-like statements it supports are… interesting. It felt a lot more flexible and “made for parsing” than good ole String.split.
I also liked some of the equality I was seeing to compare things. Since I had made up my own Date type, I had to figure out how to tell if it was greater than, equal, or less than something. Elm doesn’t have a valueOf for purity reasons, but they DO have an Order type you can use the compare function. My brain started melting (a common occurrence during these exercises) once I started having to further compare deeper parts of the date if something matched.
For example, comparing of 2017 equals 2018 is pretty straightforward:
compareDateTimeYear : DateTime -> DateTime -> Order
compareDateTimeYear a b =
compare a.year b.yearIf we call compareDateTimeYear with 2017 and 2018, it’ll return LT. But how do you compare the whole date? You make a bunch of those compare functions on the pieces, THEN put ’em in a big, nested case statement:
compareDateTimes : DateTime -> DateTime -> Order
compareDateTimes a b =
case compareDateTimeMonth a b of
EQ ->
case compareDateTimeDate a b of
EQ ->
case compareDateTimeHour a b of
EQ ->
compareDateTimeMinute a b
_ ->
compareDateTimeHour a b
_ ->
compareDateTimeDate a b
_ ->
compareDateTimeMonth a bCode language: JavaScript (javascript)She’s a big “meh” in terms of nesting, but I was proud I made her and she works.
Finally, this was my first taste of Tuples and at first I thought they were the weirdest, dumbest thing, but I was wrong… more on them later.
Day 5: Polymer Parser
Source Code | Link To Application
Day 5 was basically parsing letters. Like Day 2’s checksum parser, I don’t know why, but I found this one easy. For whatever reason, the recursion made more sense here since you’re basically “swimming over and over in a large string you keep shrinking”. I can always visualize recursion and String parsing.
The only thing I’ll point out for Day 5 is that Elm, currently, doesn’t tell you when you have dead code. For Day 5 that’s fine as even with the un-used imports, it’s still a small file. In JavaScript, the latest version of VSCode will darken the variable, showing it’s not used. However, you can sometimes have code you THINK is being used, but isn’t. I wish there was either a visual like there is with JavaScript, or some kind of compiler switch for it.
Day 6: Coordinates Finder
Source Code | Link To Application
Day 6 was one of the tougher ones. My math kept being slightly off, and I haven’t yet gotten good about extracting small parts of my algorithms… which incidentally is exactly what Functional Programming is all about; small, re-usable functions and yet here I am struggling, hah! I referred to a co-workers Python, and one simple trick he did was loading in 4 coordinates instead of all 50. This made my code a ton faster and easier to test. I also determined I was 99% there, I just had 1 bad line of code saying a coordinate didn’t belong.
In retrospect, had I known ahead of time they were looking for a Voronoi graph, I would have started there first. I did end up with some pretty looking mistakes, though.
Again, I found I made more progress prototyping algorithms in JavaScript than Elm, mainly because it was easier to debug, faster to play without types yelling at me, and I could quickly test and create new scenarios. Maybe that will change over time like it did with ActionScript 2 and 3 and types just became “second nature” when coding.
The one thing I liked about Day 6 beyond creating cool looking visualizations was getting familiar with Tuples. They’re like an Elm List, but you can get values from them and you don’t get Maybes back! This makes working with them super convenient and a lot less code. It seemed strange at first a special list type only having 2 things and I thought it was so dumb, but then I started seeing them everywhere, and made an effort to build them into my types just because they were so worth it, being easy to use. Think of {:ok, value} in Elixir or err, value in Go function return values, and you’ll get it.
Conclusions
Advent of Code 2018 was not easy, it’s quite advanced. The types of challenges are not something I’ve ever had to deal with in my 19 years of software development. Coupled with trying to learn a new language with a new way of thinking about programming, it was a recipe for pain. I’m glad I did it, though.
I’m convinced Elm for front-end is still the best. I like React + Redux, but the magic and lack of determinism and challenges of testing of JavaScript in general always have rubbed me the wrong way ONCE I LEARNED there was another way. For context, I was “done and happy” in my Model View Controller, Object Oriented Programming world of strong compiler and runtime types back in my Flash and Flex days. Taking what I’ve learned from FP, and even Elm, back to JavaScript I felt has brought a strong level of determinism in my code, made it easier to test, and made it a ton easier to blame the back-end or Ops for all of my problems. While writing UI’s in Elm without components can be painful (i.e. invest in Material Design, Bootstrap, or your own Company’s design system), it’s nice to know even without unit tests your application won’t explode in production. It’s nice to know I can write unit tests strictly on my business logic vs. “do all the things talk to each other correctly”. I haven’t done it yet (trying to at work), but I bet if I used Cypress for end to end tests, it’d be… boring… because they’d always work. Anyway, I love that level of confidence in my software.
At first I felt a little down on myself for not using PureScript at this year’s Advent of Code since it would of been a wonderful opportunity, but this has been proof that I don’t need to know Category Theory to be awesome at Functional Programming on the web.
I should point out some of the funny comments from friends online and off. Specifically about Elm’s verbosity, especially when compared to JavaScript and Python… and even Swift.
First, Elm is for the front-end. This means you’ll have GUI code mixed in with your algorithm code. A lot of people who participated in Advent of Code did not build UI’s.
Second, I have types to ensure no runtime errors; JavaScript/Python do not (yes, I know about Python 3’s opt in ones).
Third, the types are compile time only; I don’t have a runtime like Java/Swift to enforce while the code is running.
Fourth, I’m new to Elm, heh! Perhaps if I had better colors and more experience I could make her a lot more terse.
I look forward to participating this holiday season in 2019, although I have no clue what language/tech stack I’ll use.