

I describe why Node matters to me, then go over some code. Feel free to skip to the code.
Introduction
The 2nd tech I got to play with on my vacation was Node, the middleware Restify, and wiring up JSON Web Tokens for authentication.
Today, I wanted to cover what I learned building a sample application. Specifically why Restify over Express, static vs API hosting, some of the basics I didn’t know about REST API’s, CORS, Promises with Bluebird, routes, and my changed attitudes towards API development.
From Front End to Back End
My first career counselor at work last year suggested I have depth, but it’s time to increase my breadth. Specifically, as a long time front end developer, I’ve been attempting server-side API’s and database development. While I’ve dabbled in PHP and Django in the past, I never enjoyed it long term, and certainly never got paid to write any code for the server; I’m 100% client.
Node is the first time where I actually feel confident. PHP was always so hard to get my local environment setup, and my code would work differently on various servers and I didn’t understand why. Django/Python was awesome, but deployments were hard.
In Node, I code the same language on client and server, share the same libraries, running locally is easy, fast, and deployment is a lot easier, in part because of the plethora of cloud deployment services out there that didn’t exist years ago. More importantly, it has completely changed the way I work in terms of engaging with API’s. I no longer “wait for the Java developers”.
In fact, slowly but surely, my attitude over the past 2 years has gone from “Thank God for the army of server-side developers who give and save my data” to “I don’t need to wait for them anymore”. Even more poignant, I can write my own API’s, and customize THEM to MY front end screens. It’s empowering, scary, and weird.
What’s Node?
Per Wikipedia:
Node.js is an open-source, cross-platform runtime environment for developing server-side web applications.
For me, Node is 3 things: A development platform, a web server, and a REST API server.
Development Platform
It’s the platform I develop my front end applications on. I write JavaScript and test the web application I’m building. I use Node as my local web server. It runs my unit and integration tests. It runs my API server. It runs my build scripts via Grunt or Gulp.
All of this is enabled by installing Node on my, and my teams, machines.
Local & Remote Web Server
I always found Apache complicated, even though I always used stack helpers like WAMP/MAMP, etc. The settings made no sense to me. It’d work with really cool people who were just like me, yet they loved these configuration settings that I loathed. I was glad I worked with these people to figure this voodoo out. I know they were trying to help, but they actually made it worse when they said “Naw, Jesse, you could figure this out, it’s just memorizing of these settings and learning some basic Unix.” That made me feel dumb. How come you can’t just install it and have it work? Why do I have to be a neckbeard to run a website?
Now Node can do that. In 2 lines of code. And I understand (mostly) what’s doing. I don’t have spend hours Googling configurations. There’s nothing to configure unless you want to. Code, something I understand and can effectively use, is how you usually configure things.
Even better, the code I write locally works once deployed online without me having to change anything. Given how much server and client optimization I still have to do even though my “application” is considered 100% on the front end, it’s important for me to have easy access to change how certain assets are accessed by the web server. I know what needs to be optimized, and like my PHP brethren before me, I now have the powers they had to optimize the full stack.
REST API
My entire career has been around building good looking interfaces that showcase the awesome data I get from the back-end developers. Sometimes I send my own data back to them. I’ve made sure to make extra fun of the Java developers because they were often the ones who gave me the raddest data to play with.
Things weren’t always rosy. The bigger the company, the longer it’d take for me to either get data the way I needed it, or for calls to get fixed or changed. I’d sometimes get irritated and attempt to learn “What the hold up” was. Broken builds, WAR deploys gone wrong, Tomcat installations not working on particular developer machines… really complicated things that broadened my respect for these developers. “I just want some JSON, and these cats are spending weeks making a blue ball machine work… for me… what awesome people!”
I’d then lose my benevolent patience, and make 4 API calls on the client instead of my originally requested 1, mash the data together, add properties I needed on top, and call it a day. When they finally did push a new build, and my code broke, we’d play the blame game. I learned early on to layer the try/catches and error logging on thick to ensure I had crystal clarity that the back end was at fault, not me. Having my own abstraction layer over their inflexible back-end wasn’t a good thing. It made more code and harder to change & understand data.
Those days are over. Thank. God.
With Node, I now have 2 options. I can either write my own API’s or I can write my own API’s that hit their API’s. For the latter, I can do the orchestration on the server instead of the client, so while the server may have to make 4 calls, the client still only makes one.
Why Does All That Matter?
Tons of reasons.
Free Libraries. Everywhere.
Node comes with this thing called Node Package Manager. It allows me to install libraries, the same way, with the same versions or not, amongst all my team. We now can clearly spell out, like Maven in Java, what our project needs to run, what version, and NONE of that code needs to be checked into version control, speeding up development.
These libraries are for the code that runs in the browser, the code that runs on the server, and the code that builds my code. It’s all free. That’s awesome.
Speed
We don’t have to recompile JavaScript. The V8 JavaScript handles this on an as needed basis. With tools like watchers and BrowserSync, when I save a file, my server is reloaded within 1 second and my browser refreshed instantly. You can easily slow this down using syntax and style checkers, unit tests, integration test runners, transpilers which compile from another language to JavaScript, etc. Maximizing the speed of development JavaScript’s interpreted language offers requires you to ensure you have a fast, easy to use build system.
1 Platform
Having one platform for client, server, and build makes things a lot simpler, expedites development, and encourages code reuse. I write my client code, server code, and build scripts in JavaScript. I use many of the same libraries in all 3 realms. StackOverflow contains many of the same solutions for all 3.
In my experience, the “expedites development” seems offset by the gallons of unit tests and DevOps & Continuous Integration work we do, but that still reads that as a net win.
It also makes me, and my JavaScript compatriots more marketable and bad ass.
Reduces “Works On My Machine”
While Node’s 255 file path issue on Windows is still extremely disappointing, for the most part, all of my developers can get up and running in 40 minutes or less. With everything: runtime, local web server, api, unit & integration framework, code generator, required libraries downloaded &Â installed, and build system. And their machine continues to function without all their RAM and hard drive going away.
The days of sapping Java developers to suddenly become unintentional DevOps guys to baby sit our varied front end development systems because the local Tomcat/Oracle/WebSphere bloated grossness suddenly stopped working are reduced.
If it stops working, I still have mocks on the back-end that can keep my team and I moving since we can fix our own local servers.
V8 Powers
Google’s Chrome web browser, and Node, is powered by the open source V8 JavaScript Engine. It’s also one of the first places to get the working new features approved, and unapproved, by the web standards committee. Things like ES6 classes, generator functions, arrow functions, etc.
Having your server and build system have a direct line to the latest, most advanced JavaScript runtime, quantitatively, helps for speed reasons. Qualitatively, it helps your code look better, and is sometimes easier to work with.
Scaling?
Scaling is a bit murkier and complicated. You’ll hear a lot about “non-blocking I/O”. All you need to know:
- Your Node REST API should be different than your static file server.
- You can use Node for static file serving, but things like Nginx and Apache are better (I haven’t seen what Node 4.0 offers yet, nor read benchmarks, etc).
The reason number 1 is important is how Node works. When events happen, whether callbacks or events, are wired straight to the OS. Anything from a client wanting to connect, an API call from Node to another server, writing a log file to disk, to getting data from Mongo… it’s all callbacks. “Yo, here’s a function… fire this when you’re done, thanks.”
In PHP for example, it is usually more blocking I/O: The code stops and waits for that operation to finish. This results in someone, somewhere, having to queue up another thread, more resources, and extra time for context switching. For REST API’s, this can make things slower for the user. Node uses 1 thread by default for this. This makes all those calls run their logic, and end. At this point, Node just has a bunch of functions in memory waiting to be called. You get good concurrency for this as your connections scale.
For static files like CSS, HTML, images, etc. this isn’t really helpful. Apache and Nginx support sendFile (I can’t find in Node v4 does) which is the fastest way to send files.
People like you and IÂ aren’t into Node for sending files. We’re into it for creating & saving optimized JSON from simple business logic for our front end since the Java developers have bigger fish to fry. This is why my sample code uses Express for the static server, and Restify for the REST API server. The API server is where all the action and work is, Express is just there to be a web server locally, and remotely if you’re a startup… or are good at web server optimization, in which case you can make anything efficient.
The only bad news is that because of async i/o and running on a single thread, it doesn’t use multiple CPU cores. Node offers a Cluster API to allow you to take advantage of multiple cores, although it’s easier to use pm2.
What’s the Point of a Local Web Server?
I was shielded growing up in Director and Flash. I had no idea the security ramifications of allowing a piece of software access to both local disk and the server. Flash Player had a setting to allow me to test a web application locally. This was a text whitelist of sites, usually localhost, that allowed them special permissions.
Browsers don’t really have that. Instead, you run the website as something called “localhost” so it looks like a website to the browser. This causes challenges, though, because the file system you’ve created with your files all over the place don’t always match up to a URL; the address for your stuff.
Enter Express.
It’s middleware, code that runs on top of Node specifically for web specific reasons, and allows you to write code to make your web server smart. While Express is touted, and is good at, building web applications, we’re just using her for way to serve our files and operate within a secure browsing model: “All the files we’re asking for are on our website.” Website in this case being all the files in a folder that are served through Node/Express.
I always got frustrated getting this stuff to work for PHP. Python was the easiest via running python -m SimpleHTTPServer 8000. However, Python’s local web server was just for testing; what I uploaded to my web server would often run differently.
Node, assuming you’re deploying to something like Heroku or DigitalOcean (more options here), works the same because it’s the same code.
Why Does Your Webserver Need Code?
Great, but why write code? The only reason that matters for developers is Development vs. Production Builds.
For example, most JavaScript, even if using no transpiled languages, will be optimized for production by:
- concatenating the files together to reduce the number of HTTP requests
- minified to remove unnecessary whitespace to reduce file size (and long ago parsing time)
- uglified to squeeze the most file size savings out
- put in a build or dist folder
That’s just the JavaScript. The CSS, images, fonts, and associated text and json configuration/localization files also have many process steps involved with them as well.
What this means, in short, is that the files accessed are different for production builds than they are for development builds. Both builds are used. You use development builds to “write 1 line of code, test it as quickly as possible, debug it as easily as possible”. You use production builds to “give the user the fastest user experience” and “test that our optimized build didn’t break while being optimized”.
The web server needs to know what you’re testing because the file paths are different.
For example, here’s some code to detect which mode I’m operating in, and to change the folder path:
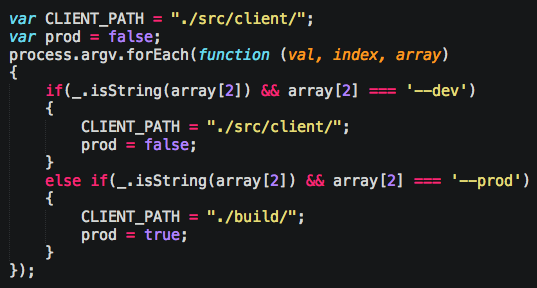
What that ensures is that when I paste http://localhost:9037/index.html into my web browser, it works the same whether that file is in src/client/index.html or build/index.html.
Also, for development builds, you’ll typically have “node_modules” and “bower_components” folders where all your JavaScript libraries are. For development, it’s fine load all the code from there, but your index.html isn’t at root, and someone asks for “bower_components/lodash/index.js”, Express needs to “know what they meant”.

Now all requests for those libraries will get redirected to the right path. Both the browser and Node get mad when you start trying to dig your way upwards in the file path like “../../” and reject you.
Finally, Node itself is usually interacted with as a command line application. When I want to launch my local webserver, I either use my build script like Grunt/Gulp to do it + a bunch of other things for me, or I just write the following in Terminal:
![]()
Notice that “–dev” is a parameter. I means to run it in development mode. There are a bunch of ways to configure scripts to run differently, and this is important when deploying code to servers, specifically around ports.
When deploying to Heroku for instance, you shouldn’t hardcode ports (a number that only 1 connect can listen on). What you can do is reference the process.ENV object to read variables passed in. In my case, when I start up the local Express web server to start listening for connections, I can read that object, and if it has a port variable, use it, else just default to one like so:
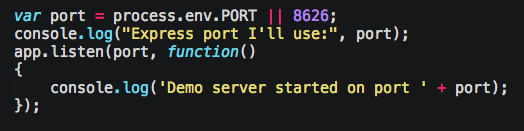
That way the code works locally and remotely.
Now you can see why your local web server requires a little coding.
Creating REST API’s
I never really understood what REST was even though I’ve been using it for 15 years. Turns out, it’s actually an architectural style, that just so happens to run on HTTP. After reading Dr. Elkstein’s tutorials on REST, it was crystal clear. It’s also clear that like all design patterns, I’ve seen people’s variations of them throughout the years which may have added to my confusion.
Fancy tech terminology aside, it USED to be just a way for me, as a client developer, to get data from the server to show, and where I saved new data I created.
Nowadays, it’s a little different in 3 respects.
Orchestration: Creating My Own API’s to Talk to Other API’s
The first thing that’s changed is that Node enables me to do orchestration quite easily. In the past, I did this on the client, which at the time, had some advantages and was one of the selling points of client application development: client application can hit multiple API’s behind the firewall.
For example, in a lot of the enterprises I’d go into, they’d have an existing authentication mechanism, a place to get data, a place to get content, a place to log things, and usually expect 3rd party services for analytics.
What this meant is my single client application, Flash or JavaScript, would be a single application hitting these 5 services. Not all of them would use the same mechanism.
Login was usually a POST request with a cookie set in the header. The data API usually expected that cookie for both permissions and roles to determine what data I should get, regardless of what my GET/POST variables said. Both would usually use JSON or XML for POST requests and responses.
However, almost all the time, there were multiple data api’s. Some were new, for specific section of the business. The XML or JSON would be in one format, and the 5 year old API would be in a different one with different looking endpoints. To show 1 screen even assuming I was already logged in would require at least 4Â HTTP requests.
The inevitable, and pointless, discussion of “May I please have a new or modified API that allows me to make 1 http request for this screen vs. 4?”
“Sure.”
:: 14 days later, we’ve refactored the UI ::
“Ok, scratch that, we need 1 additional modification, and can you please change the response format?”
I usually wouldn’t get that far, but even if I did, the technical debt of an inflexible back-end API would start building up on the client. I’d have a “Service Layer”; basically a bunch of classes that abstracted the insanity from the back-end and if something failed, my best attempt at error handling exactly where in the morass of code. I’d still make 4 HTTP calls, but at least I knew the client portion worked, how it worked, and was unit tested.
None of this had anything to do with logging and analytics.
Fast forward to today, and I can do a lot of that on the server in Node. This has a few of advantages.
- It’s fast.
- It’s cacheable for everybody, not just 1 client.
- It’s less code.
- It results in cleaner client code.
Fast
I know JavaScript. I know Node. I find the API, modify it, and the client doesn’t know any different. This assumes the data model I’m sending the client doesn’t change. Redeploying JavaScript API’s locally is instantaneous. I’m hitting real endpoints, not fixtures. I no longer have to wait for long, fret ridden Java/C#/whatever code deployments.
For real integration tests, yes, I still have to wait for those, but now much more solid and ready for those.
Cacheable For Everybody
The client nowadays has TONS of room for caching data on the client. I used this to my advantage many times when a server starting up had slow cron jobs to stash data in memcache, or the API’s were just 7 years old and slow.
With Node, you have a 2nd option. Since my API’s in an orchestration scenario are only for the client, I can use something like Redis to cache that data for all subsequent requests. Yes, the client can still cache it too, but the point here is Node becomes part of the solution, not part of the problem. Since every client is hitting that same Node API, assuming he’s not clustered or on large amounts of scaled servers, all subsequent requests are faster.
Yes, caching is hard and often screws things up more. It’s nice to have the option, though, to make a better user experience if you can pull it off, especially when I’m aggregating data through orchestrating many different back-end API’s.
Less Code
Orchestration API’s, at their simplest, are just a Promise, or series of Promises that make a bunch of API calls so your client only has to make 1. They’re typically stateless and not doing any business logic, just an HTTP request, combining XML and/or JSON together into a more client-friendly form, and sending it back.
It Results in Cleaner Client Code
This results in NONE of that being on the client. This results in easier to read code on the client, and a clear indication of where the data is coming from, and whether the single call, vs multiple calls, worked or not.
Orchestration Example
For example, here’s some Node orchestration to verify I’m logged in, if so get some data, then combine it with what’s in our local database, cache the newly created JSON, and blast it back to the client. I’ve used Promise API’s for showing how order is retained during asynchronous operations:
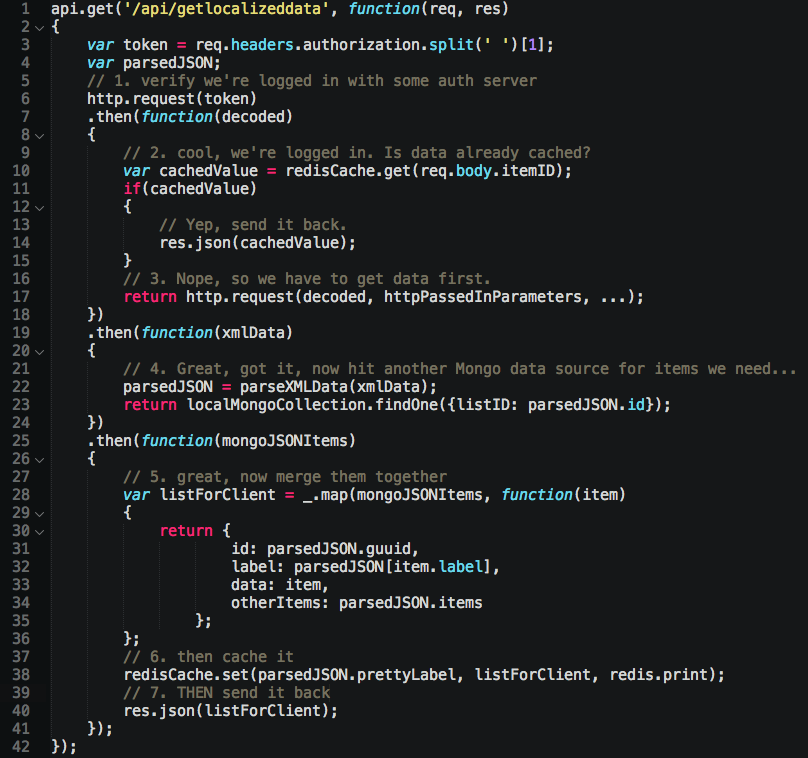
Those 3 data calls used to be on the client. Now, my client looks like this:
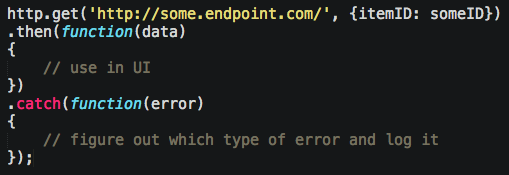
For those wishing more brevity, there are many more ways to skin a Promise, or just fall back to simpler async, or even delve into ES7-like API’s like async / await.
Consulting
Orchestration is great from a consulting stand point. I can continue what I’ve been doing for years and build client applications to hit various, usually old, API’s.
More importantly, though, I can also HELP the server developers. In the past it was a huge paradigm for server developers, which most liked, in that they no longer had to render UI’s, usually building HTML, CSS, and JavaScript on the server, and then shoving that text down to the client. With web clients (Flash/Ajax), we just wanted data, and would handle rendering the UI. This made a lot of server developers happy, and they could focus on API’s vs. API’s + application code. They were better at data, so were good at API’s. I was better at front end stuff, so was good at application code. Together, we made a great team.
Fast forward today, and things are slightly better, yet also more complicated. Once you start targeting multiple devices, sometimes you need different API’s, ones targeted at smaller screens that needs less data; or the same data, but accessed in paging fashion. Sometimes you don’t know till you build it.
The rate at which I can modify my data for my UI helps shield the older Java/C# API’s from my furious iteration.
Most helpful: Java/C# developers get I’m not there to take their job when I start writing my own REST API’s.
Writing My Own API’s
If I am tasked creating a web application, I can now finally fulfill all the roles to write my own API’s. While I’ve done this in the past to a small degree with PHP, and larger with Django, it’s a lot easier being the same build stack, and in the same language, using the same libraries.
What’s important, and what PHP, Ruby, and Python developers have known for years, is the UI gets a lot easier to build once you’re the one simultaneously building the API’s. Once you have to consume your API outside of a unit test in the real world, or you have to build the UI a certain way to work with an API, this greatly improves your design of both pieces fitting together.
In the end, the user gets a better experience, and you can more effectively plan out what it will take when discussing estimates with a designer and project manager or client.
What does a simple API Look Like?
Restify has basically the same API style of Express. Here’s a simple ping:
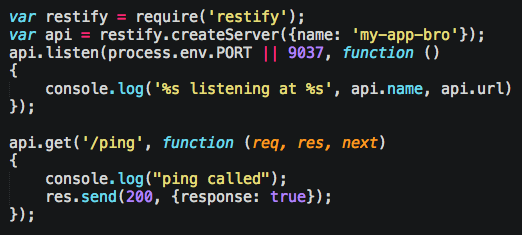
That makes ping a GET request, accessed at “http://localhost/ping”. If you load that URL in a browser tab, you’ll see the {response: true}. Now, HTTP response codes are a rabbit hole and out of the scope of this article, BUT, there are 4 we should care about, which I’ll cover later. For now think:
- 200 == legit
- 404 ==Â what you’re looking for isn’t here
- 401 == you’re not logged in
- 500 == something on my side went boom
On the client, you can go:
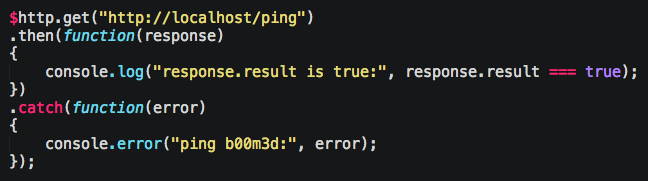
How Do I Make It Work?
Assuming you have Node installed, do the following steps:
- Open Terminal and cd to the directory where your app lives. This is an empty folder somewhere, doesn’t matter where, pick it.
- Then type “npm install restify”
- once installed, you can create a new file, and put the code I gave you in it, and save it as “server.js”
- then in your Terminal type “node server.js”
- then open your browser to “http://localhost:9037/ping” and you should see something like
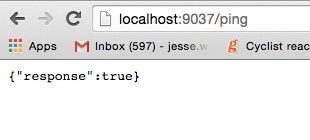
If you change your code, close your server by clicking the Terminal and choosing Control + C, or use nodemon to do it for you, maaaaahhhhn.
![]()
How Do I Debug This?
Although Node has a debugger statement like the browser, that’s ghetto. If you like IDE’s, WebStorm / IntelliJ allows you to set breakpoints on the code and step, but I like Node Inspector because you can debug directly in Chrome… which is where I spend most of my time debugging my client JavaScript. Another option is Iron Node.
You can also console.log your life away as well, and it’ll show up in your Terminal.
What are the Code Conventions?
Code wise, JavaScript ES3. There are some ES5 ‘isms, and a few use ES6 through Babel or in Node 4. Some use older versions of Node with the –harmony flag on to get these features. Some got irritated at Joyent’s slow speed and used io.js instead which has now merged (somewhat) back in.
Although it uses the V8 engine, they’ve fixed a core problem in JavaScript around modules via the require keyword. Whatever you put on module.exports is what’s returned when you require it.
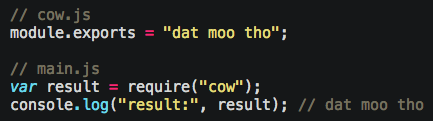
You more commonly either put functions on it:
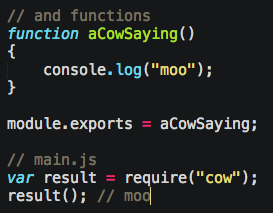
Or for larger modules, Objects that expose functionality:
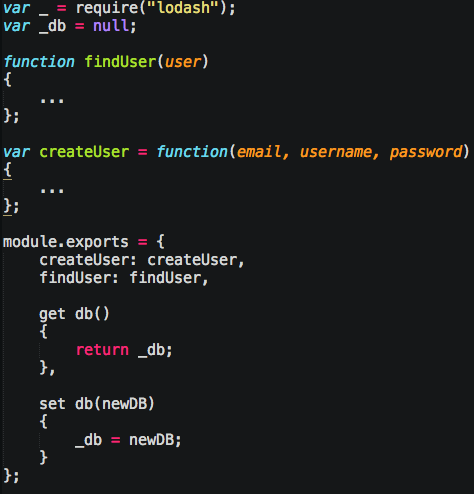
For configuration type deals, you can use JSON files in the require keyword as well.
Most basic Node API’s follow callback style of calling a method, and giving in a callback function which always returns an error as the first parameter, and the data as the 2nd parameter. If there’s more parameters, they come as 3rd, 4th, etc. Developers and documentation will constantly show “if(err)” as the first line of code, encouraging error handling. Don’t worry, they found a way to screw this up, I’ll show you in a minute.
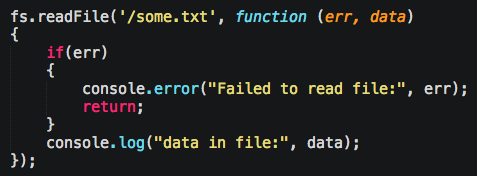
The reason Node does this with callbacks is to support their non-blocking I/O, meaning, no thread is needed to pause the code. Instead, your code is now complete, and a function is now in RAM waiting to be called at some random later time. This is how it can more easily scale (in theory) as the connection count starts climbing.
However, callbacks start to get gross when they’re nested, so Promises were born. They basically allow you to flatten nested callbacks to look more linear, and thus more easily read. It’s becoming more common nowadays to expect higher-level Node libraries to support Promise style vs. Callback style. If it doesn’t, Bluebird can promise-ify some of them automatically for you:
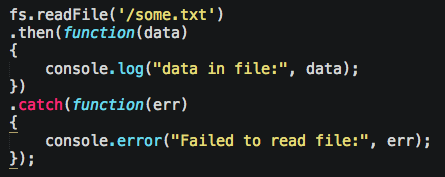
Notice the .catch can be omitted, and often is, but shouldn’t.
ES7 is bringing async/await which I’ll get into a future Mongo article, so for now Promises reign unless you count the in-between Generator Functions which will act like a await, but return an Iterator vs. a Promise. If I wanted an Iterator I’d code Java.
However, there are a few rebels who like async for it’s simplicity, and that’s cool. Otherwise, go full Bluebird.
Restify Gotchas
These aren’t really gotchas, just “got Jesse because he’s a n00b”.
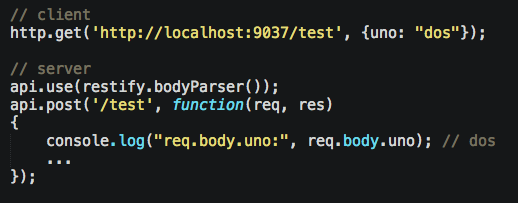
Remember to enable 3 Restify plugins so you can read query variables:
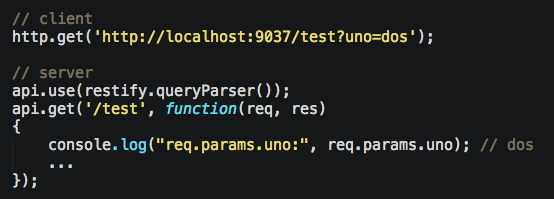
body variables:
.. and CORS. There are a bunch of weirdness to CORS that StackOverflow covers better than I. If host my files at jessewarden.com, but my API at some.random.heroku.com address, that is a cross site request. Newer browsers will make 2 requests, the first asking for permission to make a cross site request, then the 2nd request being real. The first request is usually an OPTIONS, has none of your custom headers, get/post variables. So if you see 2 requests and Chrome, now you know why. Restify, at least my version, has a bug unless I do the following:

For any custom header that doesn’t work, that’s what I had to do.
What’s This Optional Next Function?
Node throws the term “middleware” around a lot. Sometimes people use it, sometimes they don’t. Sometimes they include it, but don’t use. WAT!? It’s usually frameworks built atop of Node, like Express, Restify, Hapi, Koa, etc. They introduce the concepts of routes, and controlling access to them.
If you come from a desktop application development background, the concept of “routes” may be new to you. As someone who built, and used “routes” unknowingly for a decade in Flash/Flex, they were new to me as well. That’s often because us Flash/Flex devs ignored deep linking, and only cared about URL’s when accessing our data.
In the web world, whether client or server, it’s the opposite; the routes are the reigning king. I come from a background where if I want to show another view, I hide one and show the other, or use a hierarchal state machine to handle that, and some frameworks made this declarative (hoping Polymer does someday). In the web world, there is 1 state, and it is the URL.
There are a variety of options, but the 2 that matter are for plugins and for route resolving. Plugins, you just saw, like bodyParser: “Before we call a route, like a GET ‘/test’, parse the body String as JSON, then set it on the request variable as an object.” Most frameworks use those like crazy, and have a bunch of nexts called before your route, or “app.get” is called.
Route resolving is for a bunch of things, but the ones we care about are authentication and roles. This is actually about the same thing you do on client web applications as well so it’s cool to learn the same pattern and use it twice. For example, let’s say you want all calls to “/api/specialdata/” to be ensured to have a logged in user:
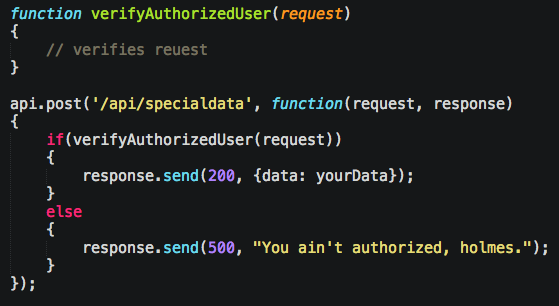
As your application grows, however, you’ll start having a bunch that do the same if statement. You fix it by adding your “before” function in there, and having everyone follow the parameter convention of next. The work differently depending on framework you’re using, but in Restify, it’s like:
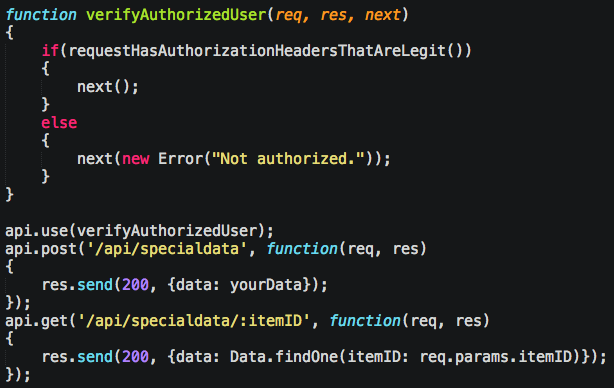
You can also pass in multiple functions, to say check something before hand, in this case, verifying the logged in user is an admin:
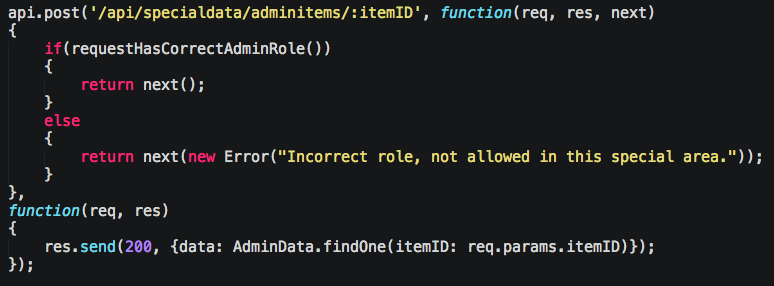
The client side routing framework, page.js does something similar which makes the pattern quite familiar once you’ve done it a few times.
Just to geek out, Koa is already positioned to handle asynchronous non-blocking next requests. Unlike Express, Restify, and Hapi, Koa uses generator functions on the next function to yield. In other languages this is basically a blocking call, but in Node, it’s just another function pointer in the stack waiting to be called at some random time in the future. It’s minor, but makes for more readable routes once this gets ES7 with async/await. Instead of a bunch of functions everywhere, you just write 1 using the yield (or eventually await) keyword. Check this guy’s example here, and you’ll get it.
In my next Mongo article, I’ll show you how you can opt into this early while still targeting ES3.
JSON Web Token
Logging in is hard, at least for me as a client developer. OAuth is near impossible to run an end to end test unless you use EasyMacro… but dude, this isn’t 1998 and we’re not playing Ultima Online, so eff that mess. It took me 5 days in Django to finally figure out CORS by reading a ton and gallons of trial and error and finally getting form + server values in sync. That was after 3 years of failures in PHP. There are a lot of ways to do it nowadays, but one that’s gaining traction is JSON Web Token. It’s also a lot easier to do given all the libraries around it.
Here’s the short version:
- Client does a post with username and password
- Server creates an encrypted token (a JSON object with whatever you want in it), then sends back to the client (or puts on HTTP only header).
- Client then makes requests and server can read this token to see if the user is legit.
This helps solve a lot of problems by making them flexible and easy to transport and decrypt server-side.
#3 is important because thenceforth, the client has a few options on making calls. It can immediately ask the server “am I logged in”? The server can either accept a temporary token that the client has given it, similar to OAuth, or just check what client JavaScript can’t: HTTP only headers. Up to you how you implement it.
Either way, this tincy call allows the client to them assume it’s logged in for a period of time and make calls with assurance. If the token expires, you can follow the standard of showing a login pop-up to ensure the user doesn’t lose their place in your app. If you give it to the client, he’s then required to put it in the request each time. Frameworks like Angular make this easy to do since they have a single place to override requests.
Reminder: It won’t be a “tincy” call if you add a ton of things to the token. General rule is the follow the JWT standard and include the claims + enough for your server to know the auth/role of your user. This object is sent every request and can be bigger unlike your typical gzipped nonce token.
Another Reminder: Don’t put the secret you use to hash it on the client.
What’s a JWT Login Look Like?
I’ll walk you through my code to give you a shorter tutorial. You can download it yourself as well. I’ll assume you’re using some client library like JQuery, Angular, or t3h Fetch. I’ll use generic pseudo code.
The client attempts to login via a post that has the username and password. I’ll assume you’ll figure https out on your own; for now we’ll use http:
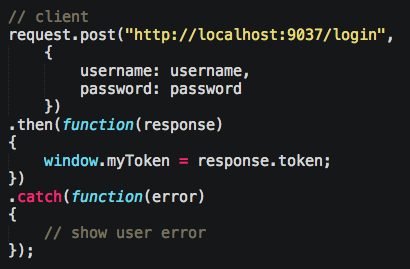
If successful, we’ll get an encrypted token back and store it in a global variable.
Cool, now let’s create an endpoint that for that cat in Node/Restify:
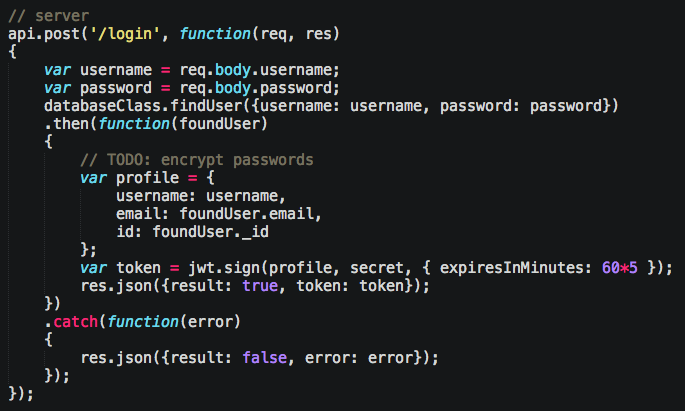
Snag the username and password from the request, find our user in the database, create a token with their information (we’re going to re-use that id and email address a lot), then send it to client. At this point, the client is responsible for putting on the header for each request to protected API’s. We do that like so:
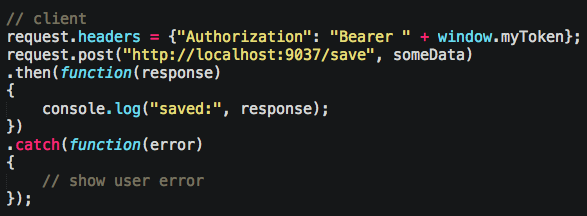
The server will be looking for that Authorization header. Also remember, these kinds of requests, where you add auth headers like that, especially with CORS, will trigger 2 requests. You don’t have to code for this; again, route middleware’s handle this type of scenario, as does Restify’s CORS plugin. You can be assured that they are called after the CORS OPTIONS request was responded to with a “yeah man, you’re good, send your request that has an Authorization header”.
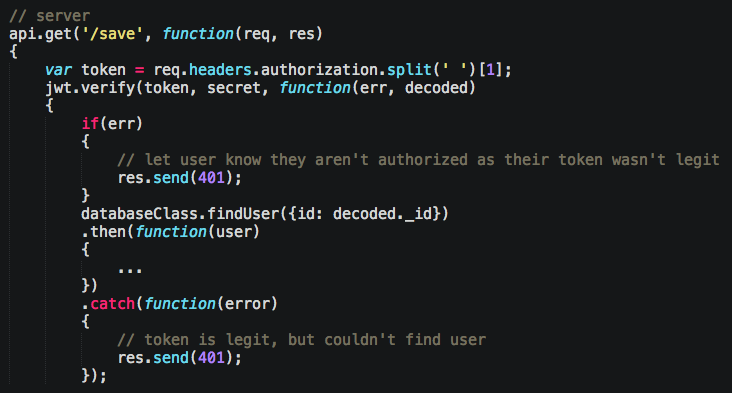
Notice we fail here if we can’t read the token using our secret to decrypt it, or if we can’t find the user in our database that’s inside of the token. This code is repeated, and, yet again, there’s a middleware for that as well. That jwt variable I’m using is part of restify-jwt, a middlware plugin for Restify. Above, I tell it all of my routes should be checked to see if they have a valid token, and exclude some special ones:
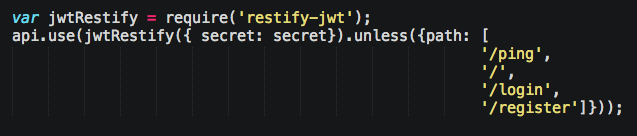
That’s all there is to it. That said, I encourage you not to send a token to a client unless you craft one with temporary permissions, much like OAuth. Instead, shove it in HTTP only headers. And encrypt it as I’m just hashing it here.
Conclusions
If I could go back in time and stop Steve Jobs & Adobe from killing Flash, I still think I’d use Node today. Given how easy it is for someone like me to use, how it works cross platform, and how it holds up well in high connection loads agains the big boys really lends credence to my using without me having to do anything to defend it. There’s nothing to defend. The language is extremely familiar to someone who’s been doing ecmascript like languages for awhile, the libraries are prevalent, and many are the same I already use on the client side. The DevOps is the same, and it naturally integrates with my build workflow.
For example, back in the Flashcom days (2002?), we dreamed of expanding the server-side ActionScript (basically the Rhino JavaScript engine on top of Java) to have an awesome, real-time data server that matched our client code. That dream has been realized today as Node + Socket.io.
If an existing client back-end team won’t let me build my own server, I can just at least build my own REST API’s to talk to their back-end. We call it the “Presentation Tier” so we don’t spook them. Anything crayon sounding, Java and C# developers brush off as harmless designer talk.
Even if a client doesn’t allow me to put Node on the server, it is still the workhorse of how I write, test, and build my client applications as well as manage my libraries. Node’s here to stay in my tool belt.
Really great. this is what I searched.
Great, thanks a lot for your writeup, helps me a lot to learn restify and related stuffs