Introduction
The last tech I got to have fun with on my vacation was MongoDB. It’s a NoSQL database, meaning, it doesn’t use the common SQL. It stands for “Not Only SQL”, but they market it to people like me so I call it “No SQL thank god”. Instead, it stores JSON objects which it calls documents. They’re stored as BSON: binary JSON.
Given my recent delusions of grandeur once I got login in Node + deployment of Node working, the world was my oyster, so I dove headlong into Mongo. Once I learned how to navigate to the real documentation, I felt right at home.
My experience with SQL helped me learn the basics which I used a lot in personal projects with PHP. Once I created a couple side projects in Ruby on Rails, and later Django, I found I really enjoyed NOT using SQL, and using code instead. Django also made it easier to understand link tables and joins.
In Mongo, it’s even simpler than that. While the queries have a necessary abstraction for CRUD operations, I’m reading and writing JSON. It’s the same stuff I’ve been using for years on the client. Even the lack of joins was easily remedied; you just store an ID to the other document.
Today, IÂ just wanted to cover the Mongo gotchas I ran into as well as some ways to make the code easier to read and write using ES7 features.
Mongo Gotchas
There a few things that threw me off guard, probably because I was having so much fun, I ignored unit tests, and really caring exactly what was going on at the query level.
Query Response
There are a variety of query responses. They’re very in depth of what occurred about the transaction, usually some form of “insertWriteOpResult”. At first I did my best to abstract these away. Coming from ORMÂ platforms like PHP, Rails, and Django that abstract the SQL syntax away from you. I just wanted to know if my data was saved, a Boolean return value; I didn’t care about all the nitty, gritty details.
Turns out that was ignorant of how Mongo works, what helpful properties are in there, and how they differ depending upon if you inserted, updated, searched, removed, etc. My unit tests for it were written around the connection and data bits, not inspecting the actual query results. That was, in retrospect, bad.
Once some of my find queries started failing because I was passing in bad search criteria, I realized I better man up, and learn all I can about the various properties of the operation results, and basically just “write better code, n00b!”.
ObjectID vs. _id
One thing that does remain similar in Mongo’s NoSQL is the concept of uniquely identifying a document by a property called “_id”. The underscore in this case implying private. It’s quite easy to query, use, and create, but SOME of my queries coming from the client got screwed up and it was all because of the datatype of my _id on those JSON objects. I used different fixtures in the unit tests, so OF COURSE they didn’t catch this bug…
Basically, you can use _id as a String or as an ObjectID for the top property on the document, but sub-properties must be an ObjectID, else when you go to query, it’ll fail if you pass in an ObjectID, and they’re all Strings, or vice versa you pass in a String, and they’re all ObjectID’s.
What I ended up doing was sanitizing the JSON that comes in and auto-converting to an ObjectID.
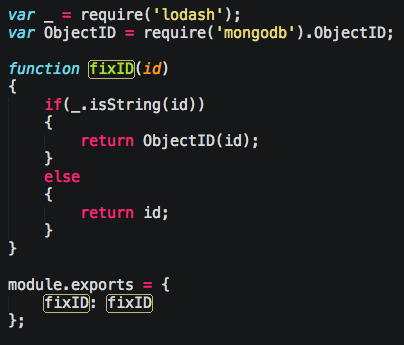
Yes, I know I should be using a GUUID and a real database ID exposed to the user.
It’s a Server, Man…
Like when I first used Redis, I thought Mongo was a big program, but in fact it’s that plus being a server. So your Node code connects to it. While the library you’re using feels like code, it’s actually issuing network requests. So I got used to opening a Terminal window, typing mongod, then another Terminal tab and starting my Node server. Eventually this should be in the build script, but it was just something I didn’t get at first when starting.
When I deploy to Heroku, it’s part of a local service they run so the same code works locally and remote by simply injecting the address:
![]()
The same applies to the database name. I had a different one locally than I had setup on Heroku:
![]()
You can setup variables in Heroku that only it can see so you don’t have to hardcode those address/passwords/etc in your code base or hide config files in .gitignore.
Writing Better Code
The first thing I noticed perusing the documentation was they weren’t using Promises, although they’re supported if you don’t want to use callbacks. Instead, they were using generator functions. I didn’t really catch why at first.
After writing a few API’s in Node, you start to get good at wrapping callbacks in Promises, or finding ways to return Promises from Promises to reduce how much async code you have to write and read. For Mongo, given that you’re making sometimes multiple queries, and inspecting results of those queries, same thing.
When you combine the two, however, things start to get verbose and long. I now realize why I never had a use case for ES7’s async/await on the client; because they’re more helpful on the server where you’re doing async things in an async-lovin’ platform.
Now, async await are not behind any special –harmony flag like generator functions were a year ago. Also note, await returns a promise, not an iterator like a generator does, so it’s simpler to use, and EXACTLY for reducing Promise usage. So how do you use it?
You have 2 options. You can use co, which is built on generators, and sadly looks like them (unless you’re a Java dev, then GET ON IT DOGONNIT!).
… or you can use the pimpness that is asyncawait. While it has 1 extra function, the syntax looks and acts just like you’d expect async await to. If you’ve used them in Dart or C#, then you’ll feel mostly right at home.
For finds, it’s ok. Here’s the Promise version:
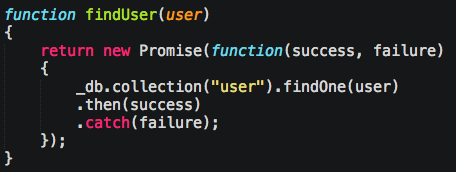
vs await:

Let’s see something more impressive when you start combining inspection of response queries and particular API calls both at the same time, such as saving a workout:
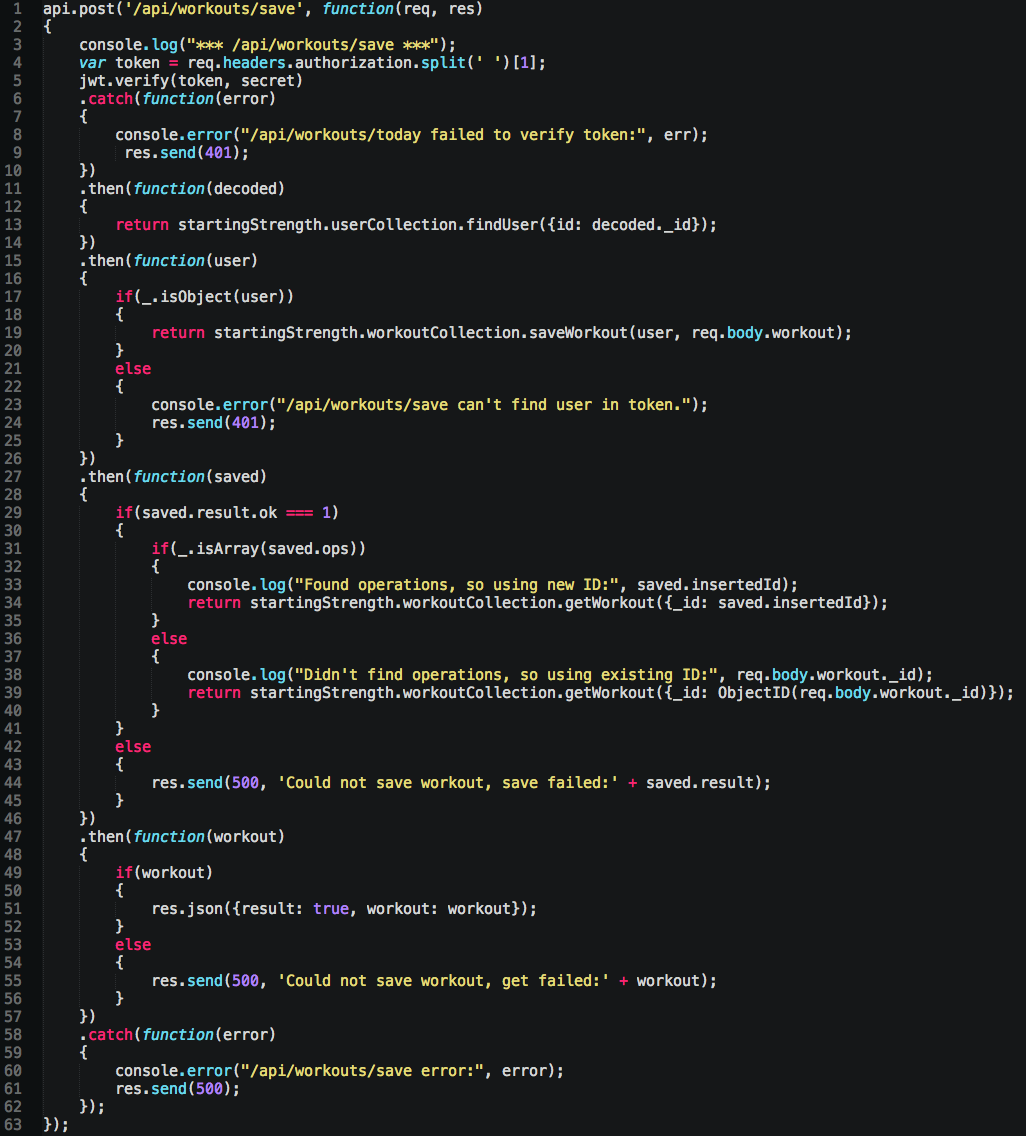
Read & decode the token, find the user, save the workout, get the updated workout based on save type, then send back to the client, else blow up.
Cool, now same code, but no more promises (or rather, hide them behind async/await):
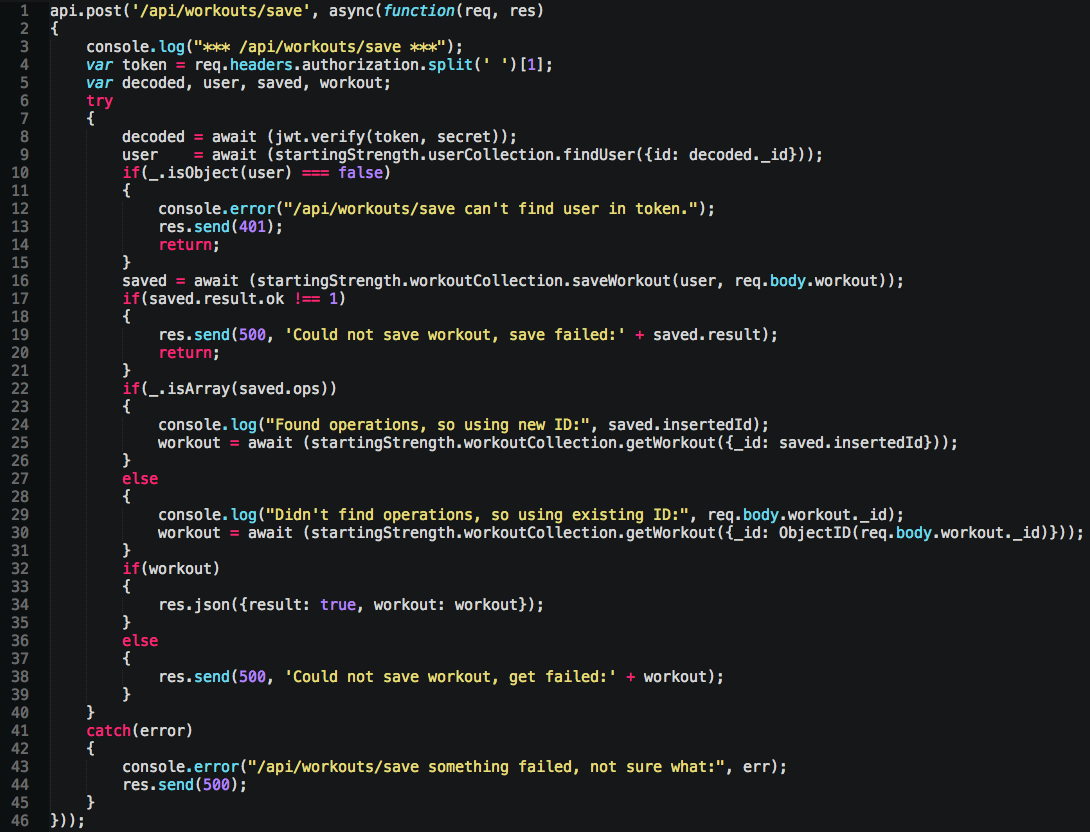
63 lines to 46, not bad, but now we have a new problem. We don’t know exactly where all the errors are coming from. In a Promise chain, you at least have an opportunity to add a catch after the Promise, and know it’s from him or Promises within him. Whereas here, you can use try catch, but… nested try/catch? Come on man, just refactor into a better API.
I bring this up because you’ll do a LOT of this in Mongo and Node together, so it helps to fail fast and provides helpful errors in case your code ends up injecting errors into someone else big ‘ole try catch like this. You want to know if the error is Mongo, Node API’s, or something else and not have to dig. I’ve always subscribed to never throwing if possible, and instead have all functions return some form of “it worked” or “not”. That way you can test with assuredness.
Good news? If the entire block explodes, the async is returning a promise, so if you start nesting async/await all through your code base, it’s still just Promises with basic error handling underneath. (lol, basic my foot!). If don’t do error handling, you’ll love async/await even more.
NoSQL Injection
This is a rabbit hole I’m still reading about. It boils down to Mongo allow dynamic queries written as plain Strings that can also be arbitrary code. You can see where that goes… straight to bad news bears. This Lukas(?) cat summarizes the problem quite well. It also adds credence to Martin Fowler’s recent quote:
Developers don’t have to be full-stack (although that is laudable) but teams should be.
Jesse, we’re glad about your new love of Mongo. However, you are NOT in charge of development for it.
Conclusions
It’s clear why I like Mongo: It was targeted at me. I don’t like converting my data to columns and rows, then doing a normalization pass, then getting creative with SQL queries. What I like is using JSON as the universal way for all of my code to pass data. It’s simple, human readable, and text I can edit & create.
I can’t wait to get an opportunity to make my Sharding more efficient. I haven’t done any yet, but I like how you have to make decisions on what’s best for your data and queries.
I really like having the power to read and write my own persistent data, and being forced to have my API’s work with that data, both front end and back. That results in better code.