There was a tweet going around Twitter, I’ve copied the text & link from image below:

The Dutch government was forced to release the source code of their DigiD digital authentication iOS app. It is written in C#.
https://twitter.com/JeroenFrijters/status/1615204074588180481
https://github.com/MinBZK/woo-besluit-broncode-digid-ap
Ok, I’ll bite. I’m ok with this code in JavaScript, not C#. Look no further to Programming Twitter for proof that there is no definition of “good code” as no one can agree if this is good or not. I’ll take this opportunity to explore the edge cases because they’re fun in Elm.
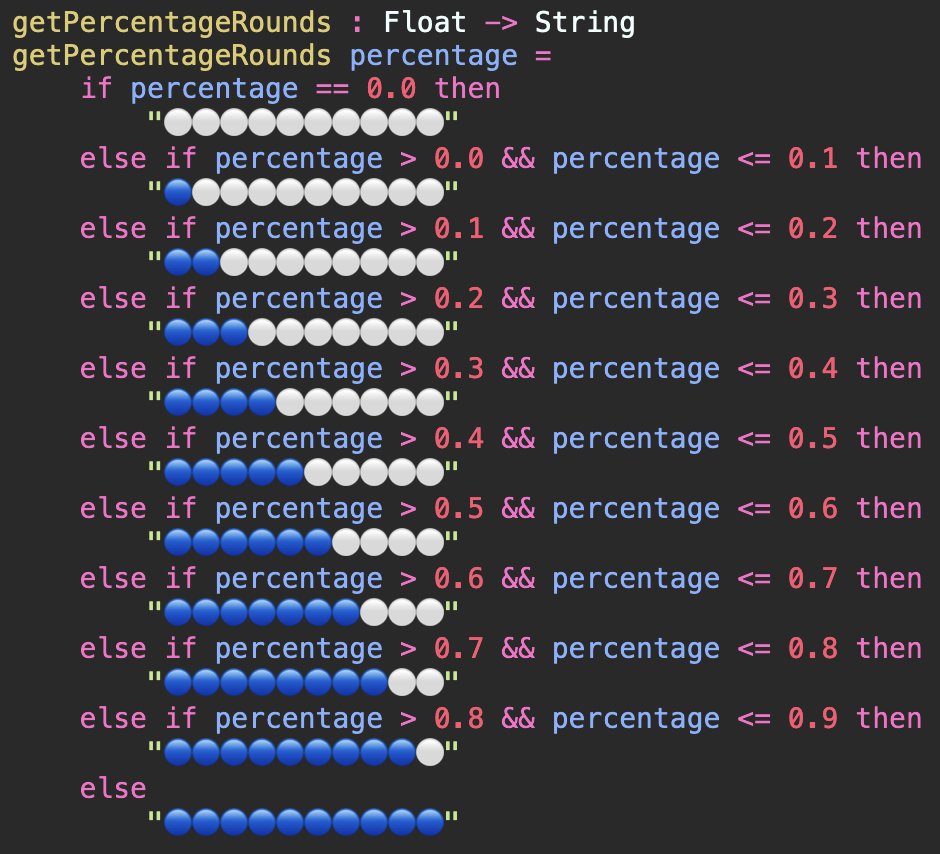
A Float in C#, JavaScript, and Elm is really high, really low in negatives, 0.0, or NaN. JavaScript doesn’t have types, but we can check for “isNaN”; same in C# and Elm. If someone passes that a function a NaN, it’ll default to 100%. Is that correct? Who knows.
Perhaps float is the wrong data type to use? Maybe a Progress union type that denotes the only allowed states, including a “what in the heck do you expect me to do here, weirdo?” state? Let’s make that. We store the “weird stuff we got” next to BruWat.
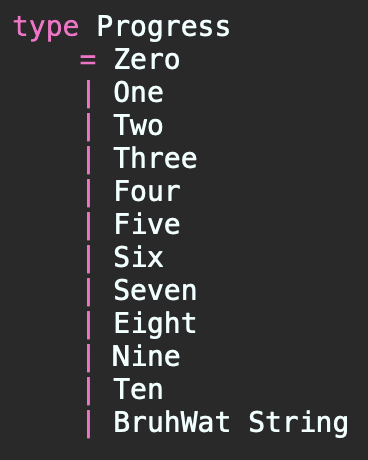
… but you may question, “Why would someone pass a NaN to this function?” Regardless of language, whether copious tests in JavaScript, or hardcore type usage in C#, TypeScript, or Elm, we sometimes go “outside of ourselves” to get data, like REST calls or user input.
Even if _your_ code is correct, users and HTTP servers can send you garbage that your correct system has no clue what it is. Do we account for that, clearly indicating it’s an error, or do simply discard it and only accept correct inputs, saying it’s someone else’ problem?
As a UI dev, I take ownership to help others debug their problems, including users. I say we include it, AND build a UI for it. Let’s adjust our function to use that new type. If you see the 🤨, then you as the UI dev, API dev, QA person, or User know we got a weird input.

This solves the NaN problem, clearly indicating “this is not what we expect”; it’s either one of the good ones like One, Two, Three… or it’s weird. Float is just a Float; it’s either good or bad, but you don’t know until you look inside it.
The Union type is safer & easier to build a UI around + logs around to let more tech savvy people know what went wrong, with details, to help them in debugging OTHER people’s code. For users, same thing, intelligent error messages.
This doesn’t solve the negative percentage problem, though; it just kicks the can down the road to someone else to solve. That’s us. Right now. Note this solves NaN, non Float strings, or if the number isn’t between 0.0 and 1.0. Narrow’s the 3 error messages to help devs & users.
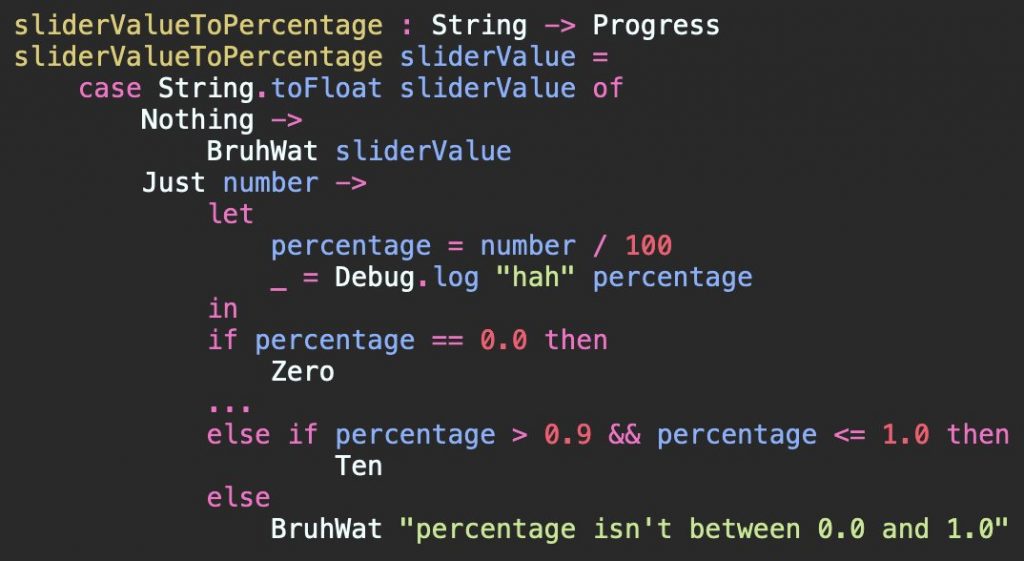
… however, who is supplying this String anyway? Well… for now it’s a trusty HTML slider. That matters because it will only supply “0”, “1”, etc. up to “100”. So we can trust the inputs for 99% of use cases. It’s JavaScript, so people could dispatch their own events/change JS


So we need to do all of this validation? No.
Do we need to check for negative percentage? No.
Do we need to check for unparseable floats? No.
… should we? Not at first, but later, yes, IF you have time. The code works. It’s safe. However, code always grows + things change.
Initial conditions, whether JavaScript, C#, or Elm are set by the developer. So in theory the slider is always set to “0” and the initial app state is set to 0. … except apps are dynamic, not static.

Meaning, you’re probably going to set that slider from some back-end call or some other piece of data. Can you guarentee THAT is not messed up?
If yes, cool, but if someone _else_, like the HTTP service does mess it up, and your parser flags it, how do you tell them?
A log? You’re not longer using the UI to indicate data issues because your UI area is clean you’ve got strict parsers. Do we remove BruhWat because we’ll just get an HTTP error if our REST API sends weird data?
Years of UI dev says API devs have it rough and we should help them.
So we’ll keep the raised eyebrow + debug information emoji for UI, API, and QA, but a user will probably never see it. If they do, it’s our breadcrumb, our brown M&M.
“A user see’s a ‘mean emoji’?”
“Ah, yes, I know where to look…”
That said, if don’t care about HTTP dev’s well being, or you’re never using dynamic data to populate sliders, then the original code works just fine. Code bases, again, grow and the environment around them changes. It’s better to be defensive, safe, and informative.
Is this C# code good? Yes. Can it be improved, maybe, but doesn’t have to be and be fine as is. Happy path dev is still good. If you have time/power/energy to shield it from known unknowns, great, go for it. Don’t stress, just try when you can.
You can see the UI and code for the happy path.
You can also see the UI and code for the enhanced code as well.