Primitive Obsession is problem where you have a function with multiple parameters of the same type. This causes a risk that you’ll get them in the wrong order, it causes readability problems, and can cause compiled languages to “compile” but still result in incorrect code when it runs.
To solve primitive obsession, one way is to utilize a class/record/object instead, group all the function parameters into that, and your function only takes 1 parameter. This ensures you can’t mess up order because the function only takes 1 parameter, and because Records/Objects don’t care about field order.
However, there may be domain modelling reasons you want these primitive types, and don’t want to create an Object just for 1 function. Perhaps these low-level primitives are helpful and used in multiple places, further improving the readability across your codebase. How can you avoid primitive obsession, yet still retain descriptive types? You do it by wrapping your primitives into actual types. This varies by language, but is basically the same concept; making it a distinct “thing”, whether class/record/object/type.
Seeing how you approach solving this in multiple languages, and the tradeoffs, will help give you a better understanding of how it’s a core problem regardless of language, as well as some of the various approaches. This will make your code more likely to work, if you use a compiler it will ensure the compiler helps you, and ensure your code is readable to you and your coworkers, now and in the future.
Code for examples below is on github.
Companion video below.
Code Example
All 6 ½ code examples do the same thing. They parse primitive data from an outside source. Data that doesn’t come from inside your language is often the #1 source of bugs, whether reading from disk or an HTTP call for example. Dynamic languages will often have runtime validation, whereas typed languages will ensure the data is being parsed into a safe type. Both, however, will validate at runtime in case the data isn’t correct.
Our example is parsing a Person from a string team, string name, int age, and string phone number.
jesse = get_person(Team.Red, "Jesse", 42, "804-555-1234")
print(jesse)Code language: PHP (php)There are validator functions that check the contents of the string to further ensure it looks legit. If not legit, the function will return an Error describing why.
def validate_name(name:str) -> Result[str, str]:
# can't be 0 characters
if len(name) < 1:
return Failure('name cannot be blank')
# can't be a bunch-o-blanks
if reduce(all_blanks, name.split(), True) == True:
return Failure('name cannot be a bunch of blanks')
return Success(name)Code language: PHP (php)These validators are composed together into 1 big function: if they work, it’ll make a Person using that data. If not, it’ll return an Error telling you why it failed.
validate_name(name)
.bind(lambda _: validate_phone(phone))
.bind(lambda _: validate_age(age))
.bind(lambda _: Success(Person(team, name, age, phone)))Code language: CSS (css)They key bug in all of the code is when you accidentally get the parameter order wrong. It’s supposed to be “Team, Name, Age, and Phone” but swapping the Name and Phone could happen by accident. This is the correct order:
get_person(Team.Red, "Jesse", 42, "804-555-1234")Code language: JavaScript (javascript)This is the incorrect order:
get_person(Team.Red, “804-555-1234”, 42, “Jesse”)
You’ll get a runtime error that says the phone number is wrong, and you’re like “The Phone number looks good to me, how weird…”. This is a logic problem AND a readability problem; the function itself has primitive values; string and numbers, next to each other and so there is no one to help you get the order right, nor any runtime validations to help ensure you’re dealing with the right type.
Python and MyPy
Python is a dynamically typed language, just like JavaScript, Lua, or Ruby. However, Python 3 has a Typings package that you can import and add additional typing information to your code. It is ignored at runtime, but tools can help, and if you like types, it can help in readability.
Using mypy, a type checker for Python, it can read your Python code, basic typings, and the Typings library to give you some good compiler errors. It doesn’t compile anything, it just reads your code and tells you where you have problems, just like a regular compiler would. However, using primitives with a compiler doesn’t really help. Things like string and int are way too broad. The compiler will assume all strings are ok. That’s not correct; a name string and a phone string are not the same.
Let’s read our get_person factory function’s type definition:
def get_person(team:Team, name:str, age:int, phone:str) -> Result[Person, str]:Code language: CSS (css)You can see the Team is an Enum, so if we type something like Team.green, an option that isn’t in the Enum, mypy will yell at us in a good way:

Very cool. Sadly, though, wring our function correctly like this passes the mypy check:
get_person(Team.Red, "Jesse", 42, "804-555-1234")Code language: JavaScript (javascript)As does swapping the order incorrectly of name and phone:
get_person(Team.Red, "804-555-1234", 42, "Jesse")Code language: JavaScript (javascript)
Bummer 😞.
The way to fix so the compiler see’s the strings as different types, and us as the reader, is to actually define them as different types. The Pythonic® way to do that is by using Dataclasses. While Dictionaries are a good data type in Python over class instance, Dataclasses offer some features which can help when you have data. Typically classes in Object Oriented Programming are for behavior and data, and Dataclasses were invented for when your class is just for holding data.
We’ll define a Dataclass like so:
@dataclass
class Name:
name: strCode language: CSS (css)Then update the type in our function from strings:
get_person(team:Team, name:str, age:int, phone:str)Code language: CSS (css)to names:
get_person(team:Team, name:Name, age:Age, phone:Phone)Code language: CSS (css)A lot more readable. This also includes making the invoking of the function more readable too:
get_person(Team.Red, Phone("804-555-1234"), Age(42), Name("Jesse"))Code language: JavaScript (javascript)Notice the order is incorrect. If we now use mypy to validate it:

Much more useful. Even in a “dynamic language”, using improved type definitions that aren’t primitives, our type checker can now help us.
However, our dataclass used to print nicely, now it’s a bit scrunched.
Person(team=<Team.Red: 'red'>, name=Name(name='Jesse'), age=Age(age=42), phone=Phone(phone='804-555-1234')Code language: PHP (php)We can enhance the string method on the dataclass to print nicer simply by dotting the properties:
@dataclass
class Person:
team: Team
name: Name
age: Age
phone: Phone
def __str__(self):
return f'Person(team={team_to_str(self.team)}, name={self.name.name}, age={self.age.age}, phone={self.phone.phone})'Code language: CSS (css)Now when we print it out, it’s more readable:
Person(team=red, name=Jesse, age=42, phone=804-555-1234)TypeScript Type Records
TypeScript is a typed language that compiles to JavaScript. It’s greatest strength is also its greatest weakness: integration with JavaScript. This means you can lose type information as well as running into nominal typing problems; meaning many of the types look the same as far as the compiler is concerned, but they aren’t.
Here’s the same problem illustrated in TypeScript, we’ve typed our getPerson function:
const getPerson = (team:string, name:string, age:number, phone:string):Promise<Person>Code language: JavaScript (javascript)TypeScript cannot tell the difference between “name” and “phone”. So both of the below will compile successfully, but the 2nd will fail to run correctly:
getPerson("green", "Jesse", 42, "804-555-1234") // correct
getPerson("green", "804-555-1234", 42, "Jesse") // incorrectCode language: JavaScript (javascript)One thing you can try is a type alias. It’s simple “another name for”.
type Name = stringOur “Name” is “another name for a string”. Cool, let’s do all 4, 2 for our Teams, and the rest their primitive equivalent:
type Team = "blue" | "red"
type Name = string
type Phone = string
type Age = numberCode language: JavaScript (javascript)Then we can re-type our function:
const getPerson = (team:Team, name:Name, age:Age, phone:Phone):Promise<Person> =>Code language: JavaScript (javascript)Now when we do things wrong, we can get a code hint in our IDE, VSCode, without even running the compiler. Look when happens when we hover our cursor over the “green” string which represents our Team type:

Very cool. Sadly, though, it’s only half way. The problem with nominal typed languages is that the “structure” of Name and Phone are the same… strings. So it’s not able to see that the Phone and Name are in the wrong position.
Let’s take it a step further and make it a record type:
type Name = {
name:string
}Now when we create these inline, the compiler can tell us 2 new things:
- if the record you’re creating is incorrectly shaped
- if those records are in the correct position or not
As you see here, notice when we hover over the phone, it tells us the name field is incorrect, and we should be using phone instead:

And if you get them in the wrong order, it’ll tell you the types don’t match:
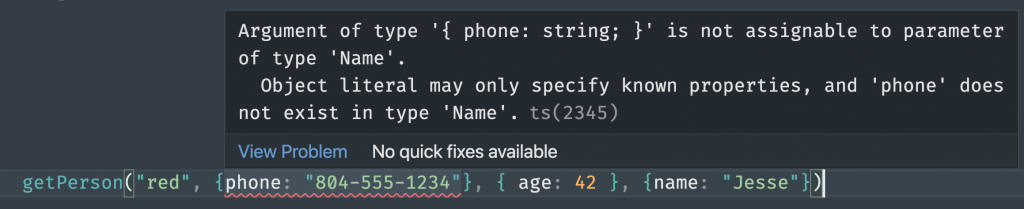
MUCH more helpful. The compiler ensures we both make ’em right, and place ’em right.
… however, all our other code was dealing with just the primitives. Thankfully, TypeScript allows us to safely destructure:
const getPerson = (team:Team, {name}:Name, {age}:Age, {phone}:Phone):Promise<Person> =>Code language: JavaScript (javascript)Now the entire body of the function can use the name, age, and phone without having to treat it like a record. Minor, but super helpful. In Python, we had to add a function to the Dataclass, and do this destructuring in the body of each function.
Because of TypeScript’s integration with VSCode, we can fix type errors while we code, without waiting for TypeScript’s famously slow compiler, a much faster workflow, more readable, and more correct before we even compile.
ReScript Alias, Variant, and Records
ReScript is a soundly typed language that compiles to JavaScript, much like TypeScript. The difference is the compiler is one of the fastest on the planet, much faster than TypeScript. Secondly, the types are more correct, offering more guarentee’s when you compile. Lastly, it has variant types which allow us more flexibility in differentiating our types.
Despite all this awesomeness, it still suffers from the primitive obsession ordering problem:
let getPerson = (team:team, name:string, age:int, phone:string) =>Code language: JavaScript (javascript)Which means when we call it with the parameters in the wrong order, the compiler shows no problems:
getPerson(Red, "804-555-1234", 42, "Jesse")Code language: JavaScript (javascript)We could try the named aliases like we did in TypeScript, but ReScript treats those as structurally the same, just like TypeScript. While the Team works, the rest do not:
type team
= Blue
| Red
type name = string
type age = int
type phone = stringReScript, however, has an advanced form of type aliasing with a named constructor:
type name = Name(string)You’ll notice it looks much the same as type name = string, but the difference is the constructor, capitalized “Name”, helps it differentiate between Name and Phone… because there are 2 named constructors which are named different. Yes, both take a string as the first and only parameter, but both are distinct as far as the compiler is concerned.
If we define all of them as named constructor aliases:
type name = Name(string)
type age = Age(int)
type phone = Phone(string)Then change our function to use explicit types (ReScript can infer the types, I’m just typing it manually so TypeScript users will feel more comfortable reading the syntax):
let getPerson = (team:team, name:name, age:age, phone:phone) =>Code language: JavaScript (javascript)Now when we attempt to call it in the wrong order, the ReScript compiler and IDE plugin will show problems:
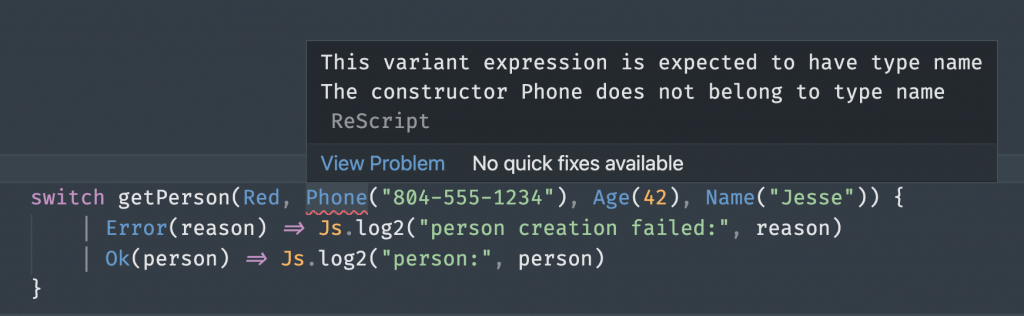
And our function is more readable because of the explicit types. Like TypeScript, we can now re-use these named types elsewhere, whether in other functions or records, further helping strengthening more code and making it holistically more readable.
Elm Aliases and Named Types
Elm is a soundly typed language, compiler, and package manager for building web UI applications. Elm is famous for it’s “if it compiles, it works” catch phrase and nice compiler errors. However, here you can see, we’re defining our function using primitives:
getPerson : Team -> String -> Int -> String -> Result String Person
getPerson team name age phone =Code language: JavaScript (javascript)Which means the famous compiler error messages will be absent because Elm doesn’t see anything wrong with this code:
getPerson Red "804-555-1234" 42 "Jesse"Code language: JavaScript (javascript)… which means the 2 most famous things are missing 😔. Let’s help Elm to help ourselves get back in the fun Elm place to be. We could try type aliases like in ReScript:
type alias Name = String
type alias Age = Int
type alias Phone = StringCode language: JavaScript (javascript)… but even if we update the function, Elm still thinks they’re both strings, and thus are the same shape, so no compiler error:
getPerson : Team -> Name -> Age -> Phone -> Result String Person
getPerson team name age phone =Code language: JavaScript (javascript)So copying ReScript’s type alias named constructor syntax, we can do the same in Elm to help the compiler tell the 2 are completely different types:
type Name = Name String
type Age = Age Int
type Phone = Phone StringCode language: JavaScript (javascript)The syntax looks like the Python Dataclass or ReScript Variant. Now hovering over the function gives us compiler errors in our IDE before we even attempt to save the file:
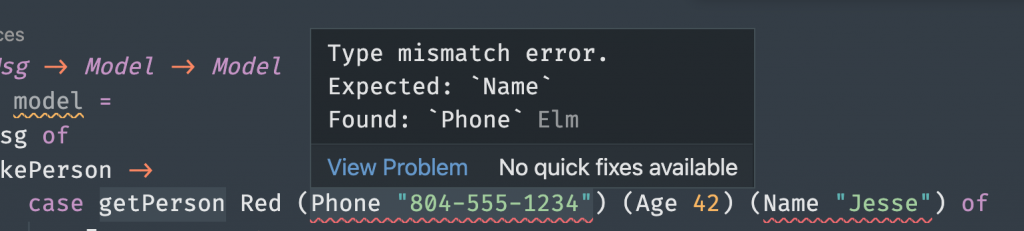
GraphQL and JavaScript
You’ve seen how we can improved languages with types that ensure the type checker or compiler can help us. However, this is just for our code. What if we have client code talking to server code, or server code talking to some other server code? How do you enforce types across the REST boundary?
GraphQL. It’s a schema format used to type your data, just like you’d do in TypeScript, ReScript, or Elm, and ensure it keeps that type information when it’s sent and received across the wire. Libraries are built on top of it, just like JSON, to ensure everyone interops.
However, you still have to model well. In GraphQL, you can define functions, called mutations and queries, to take in some data, and return it. We’ll model our save person like we’ve been doing above with 1 slight modification: instead of primitives, we’ll take in a Data Transfer Object; a PersonInput:
type Mutation {
createPerson(person: PersonInput): Person
}In GraphQL, they want you to model your inputs separately form other data, so PersonInput and Person are basically the same. You follow the naming convention of “Input” at the end of your input types to differentiate them from regular types:
input PersonInput {
team: Team!
name: String!
age: Int!
phone: String!
}
type Person {
team: Team!
name: String!
age: Int!
phone: String!
}Code language: CSS (css)The exclamation points (!) mean the value cannot be null.
Our GraphQL schema is defining a savePerson function that takes in a person and returns the person the server creates. However, as you can see, the name and phone are both strings so it’s difficult to tell them part. Additionally, we’re using JavaScript on both the client and server, so it’s difficult to enforce that order. The most common way of avoiding order problems in JavaScript is the lightweight way to get a DTO: Using an Object.
Take the client code that makes the call to our GraphQL server:
const savePerson = (team, name, age, phone) =>Code language: JavaScript (javascript)So we have 2 problems: JavaScript’s function, and the primitives we’re using to model our Person types. Let’s fix GraphQL first. A better way is to clearly define what a Name and Phone are… as distinct types. Yes, they’re still primitives, but we can clearly define what they are from a readability perspective, and have GraphQL see them as 2 distinct things:
input NameInput {
name: String!
}Code language: CSS (css)Now doing that with the rest, we can re-define what GraphQL expects from the client:
input PersonInput {
team: Team!
name: NameInput!
age: AgeInput!
phone: PhoneInput!
}Code language: CSS (css)Now you could do the inline Object way or create a helper function which I think is more readable.
const Name = name => ({ name })
const Age = age => ({ age })
const Phone = phone => ({ phone })Code language: JavaScript (javascript)The Name and the Age use the function way, but the phone does the inline Object; either is fine, I just like the first:
savePerson("red", Name("Cow"), Age(13), { phone: "771-555-1234" })Code language: CSS (css)Now, since JavaScript doesn’t have types, we have to rely on the Apollo server to tell us if we got the types wrong; think of it as your remote type checker. When we call GraphQL with the order wrong, we can read the errors to figure out why:
savePerson("red", { phone: "771-555-1234" }, Age(13), Name("Cow"))
.then(console.log)
.catch(error => console.log(error.networkError.result.errors))Code language: JavaScript (javascript)Which when called will result in an Apollo error response:
[
{
message: 'Variable "$person" got invalid value { phone: "771-555-1234" } at "person.name"; Field "name" of required type "String!" was not provided.',
extensions: { code: 'BAD_USER_INPUT', exception: [Object] }
},
{
message: 'Variable "$person" got invalid value { name: "Cow" } at "person.phone"; Field "phone" of required type "String!" was not provided.',
extensions: { code: 'BAD_USER_INPUT', exception: [Object] }
}
]Code language: JavaScript (javascript)Very cool. Much better than no error and bad data as before.
Dhall Types and Records
We’ve talked about code, and types across networking boundaries. We’ve seen how using types allows us to compile to dynamic languages with guarentee’s. Code configuration is often the most brittle part of our stack, yet because it’s “so small”, we often don’t invest any tooling for it. We can remedy that using Dhall: a way to write in a soundly typed language that compiles to JSON or YAML.
IAM Roles in AWS allow anything you deploy to AWS to “do things”. It can only do things it’s allowed to do. No IAM Role allowing something? Your code will fail with a permission error. Worse, you can deploy a new IAM Role and break all of your existing code and infrastructure; because suddenly it couldn’t do things that it could seconds before. IAM Roles are extremely important and extremely dangerous to screw up. We’ll use Dhall to create these IAM Role policies; JSON documents that state what something is allowed to do.
In our example, it’ll allow our Lambda function to log. We’ll write ARN’s, or “URL’s for infrastructure”. They all have a specific format and order you can learn, but there’s no need for you to know ARN syntax. Just know for ARN’s, “order matters”, heh.
Typically in Dhall, you’ll write your variables and functions to render those to JSON/YAML. However, Dhall allows you to use primitives as well, in this case Text. Here’s how we’d render a log group using your lambda function name, and your AWS account ID:
let renderLogGroup
= \(region : Region) ->
\(lambdaName : Text) ->
\(accountID : Text) ->
"arn:aws:logs:${renderRegion region}:${accountID}:log-group:/aws/lambda/${lambdaName}"Code language: JavaScript (javascript)It’s a function that takes a lambda name as text, and an accountID as text, and returns an ARN string with them in the proper place inside. Already, you can see the problem; “Text and Text and Text….”.
If you have a 50/50 chance to get the order right.
let AccountID = "010101010101"
let validateJWTLambdaName = "validateJWT"
let Region = < East | West >
renderLogGroup currentRegion validateJWTLambdaName AccountID
# or... wait... is it
renderLogGroup currentRegion AccountID validateJWTLambdaNameCode language: PHP (php)Here’s what it looks like if it’s correct:
arn:aws:logs:us-east-1:010101010101:log-group:/aws/lambda/validateJWTCode language: JavaScript (javascript)And here’s if it’s wrong with the lambda name and account number switched:
arn:aws:logs:us-east-1:validateJWT:log-group:/aws/lambda/010101010101Code language: JavaScript (javascript)… oh yeah, and all of your code now fails to log, well done.
Instead, we can create typed records in Dhall to ensure the compiler knows the differences between the 2 arguments.
let AccountID = { id : Text }
let LambdaName = { name : Text }Code language: JavaScript (javascript)Yes, they’re Text, but they’re now wrapped so the compiler can help us. We can define our function’s parameters from text:
let renderLogGroup
= \(region : Region) ->
\(lambdaName : Text) ->
\(accountID : Text ) ->Code language: JavaScript (javascript)To actual types:
let renderLogGroup
= \(region : Region) ->
\(lambdaName : LambdaName) ->
\(accountID : AccountID ) ->Code language: JavaScript (javascript)Now, when you attempt to do the wrong order:
It tells you that you’re missing the name property, and incorrectly included the id property.
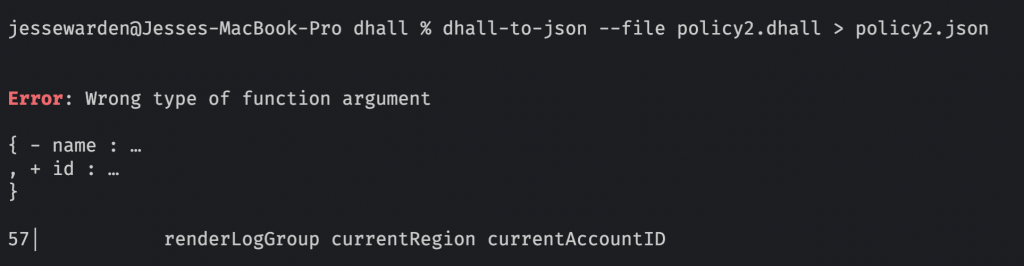
Much more helpful.
Conclusions
As you can see, primitive obsession is used a lot when you’re parsing data. This is also the most dangerous place when you’re getting data that didn’t originate from your program, and could be shaped incorrectly, resulting in bugs. When you’re in this area, it’s helpful to avoid using primitives, and wrap them in custom types. For typed languages, this will ensure the compiler can actually help you differentiate between the different pieces of data, ensuring they are in the correct order. You can totally use Records/Objects too to avoid the order error, but you loose the ability to use those individual pieces as types throughout your module or program. This ensures that when you compile, things are more likely to work.
Secondly, being able to see configureLogger(MockModeOn, LoggerStandardOutOFF) vs. configureLogger(false, true) is a lot more clear what those booleans do. Avoiding primitives and using custom types results in a lot more readable code and error messages.
Code for examples above is on github.