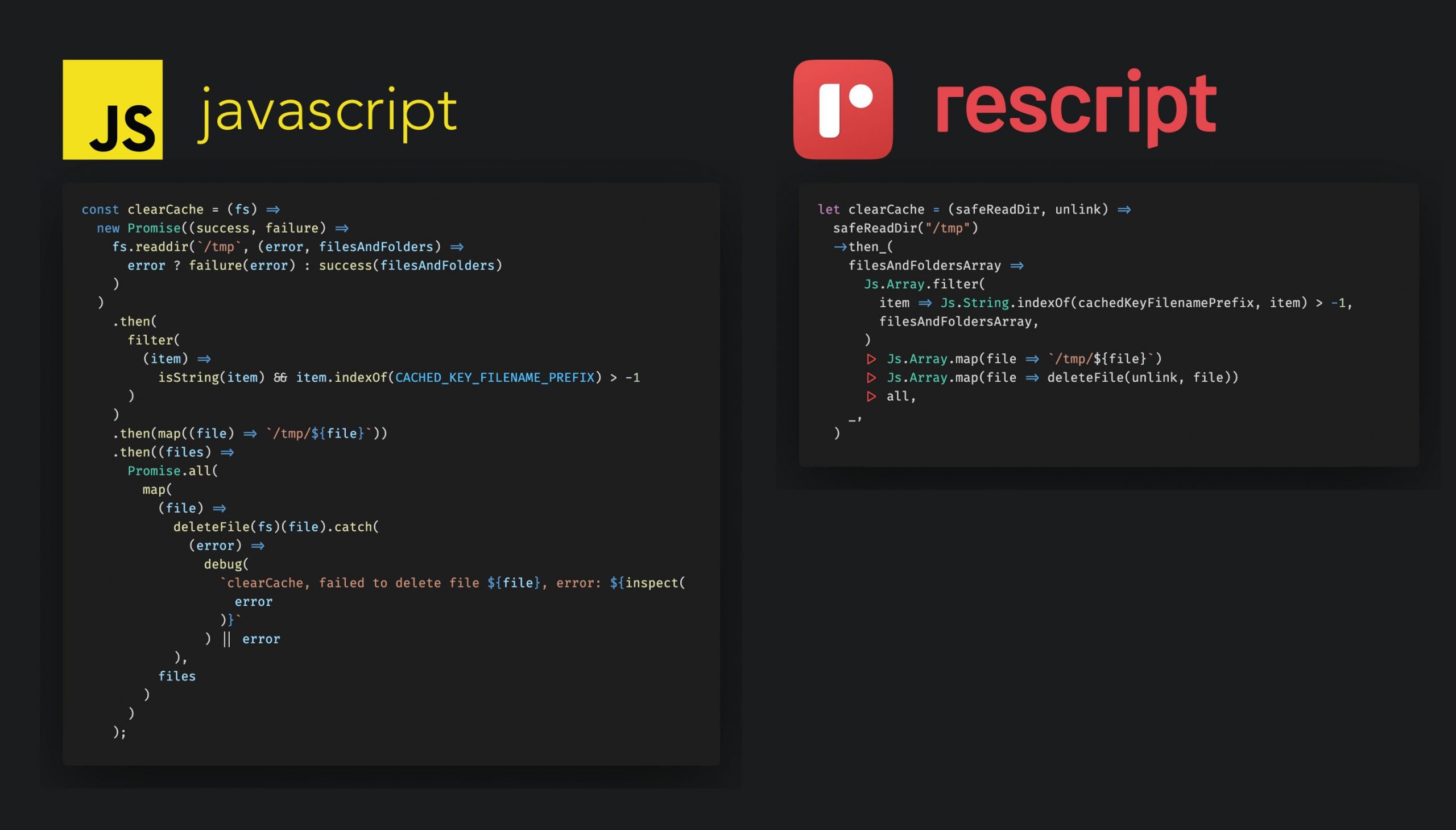
Introduction
I spent the past couple of years playing around with Reason, which later split off into ReScript: the OCAML for JavaScript developers. Last weekend, I finally was productive. I wanted to cover what I’ve learned in the past 2 years, and even this weekend. My hope is it will inspire you to check out what ReScript has to offer compared to TypeScript.
Early Struggles
Despite it’s much cleaner syntax compared to TypeScript, I still struggled to make a lot of headway in learning Reason/ReScript. ReScript’s types are powerful, but like TypeScript can get pretty deep, quickly. Like TypeScript, it can integrate with JavaScript libraries “as-is”, which means some of the types won’t always make sense, nor are they consistent, or they may be overly complicated because of the way the JavaScript library was designed. While the branding and duplicated documentation (Bucklescript vs Reason, then ReScript last Fall) was confusing, I got over it and the docs for the most part are pretty good, and they provide enough examples.
It was quite frustrating because ReScript looks a lot like JavaScript. The way it does types means that you don’t have to add the types yourself most of the time, which results in even more lean code. ReScript doesn’t do anything special with side effects. It doesn’t have Category Theory (mostly) from Haskell. In short, it should be pretty easy to learn, right? That drove me nuts to no end. I didn’t get why I wasn’t making a lot of progress given all the similarities and the lack of new things to learn.
F#
I took a break and started exploring F#. Like ReScript, F# is based on OCAML. The difference is F# had to incorporate a lot of Object Oriented Programming constructs so it could more easily compile to .NET and remain compatible with C#, Microsoft’s Java. It also has way more years & engineering effort money behind it. While the docs aren’t that great, I did manage to get up to speed being productive building Lambdas in AWS. Like ReScript, you don’t really need to add types yourself to functions; the compiler is smart enough to “know what you meant”. I immediately noticed that the compiler errors for F# just… made more sense. Granted, nothing is as good as Elm’s compiler errors, but still, I felt like I had more of a chance to figuring them out on my own without googling.
Lesson #1: When I started new ReScript projects, I started small and did NOT attempt to integrate with JavaScript early. I needed to learn the compiler error messages in just normal ReScript code. Once I got comfortable with those, it was easier to start tackling Promises and integrating with JavaScript.
Typically compiler errors are your friends, and you utilize them as a tool to refactor not just with unit tests. However, I felt like in ReScript I was just trying to make the compiler happy and wasn’t really learning why they were mad. Starting with much smaller examples in just vanilla ReScript, I started to get what the messages meant, AND I could start reading the various type definitions it would request.
Elm has the same problem; it’s so good that you just don’t add types to your functions.
add :: Int -> Int -> Int <-- you don't need to add this
add a b = a + bCode language: HTML, XML (xml)ReScript is the same:
let add = (a:number, b:number) => a + b <-- you don't need to add the :number stuffCode language: JavaScript (javascript)While this behavior in the beginning is good… when you get compiler errors saying things like “you did a string -> int, why?”, you get confused because you intentionally figured “well, the compiler will figure that out so I don’t have too, right?” I did myself a bit of a disservice to just rush to ReScript’s value vs. learning the compiler errors first. There is just a bit more learning curve there compared to F# or Elm.
JavaScript Integration
While the time spent learning was valid, the epiphany I had this weekend I think really got me over a massive hump in being productive with ReScript. Specifically, integration with JavaScript. Now ReScript has a ton of ways you can do it, but what all of them mostly have in common is they are typed in some way. When you read that at face value, or even the documentation, your brain immediately goes into “Ok, so fetch takes an Object that has some optional types, some are Objects too and some are Strings, how do I type this, hrm…” That was my 2nd mistake.
Lesson 2: You do not have to add types to the JavaScript you are given. You can instead modify it to make it easier to work with, or create a new interface in JavaScript for yourself that’s much easier to type.
I don’t know why I didn’t grok that at first, I guess from my time with TypeScript and Definitely Typed where other people handle it, I guess? In that workflow you npm install, then use it. In ReScript, my workflow is npm install, then ensure we can easily integrate and if not fix, then use it.
For example, if you want to use Node.js’ readFile, the first option is to just bind to it:
@module("fs") external readFile: string => ??? = "readFile"Code language: JavaScript (javascript)Immediately I have a few problems, though. It takes a filename as a string, but doesn’t return anything. Instead, it takes a callback. This is an older way of doing Node.js, and many still use it this way vs the new fs Promise API. ReScript supports callbacks and this and modelling it, but… if I wanted to use noops, callbacks and the this keyword, I might as well stay in wanna-be OOP JavaScript. I came to ReScript to be Functional, and I expect my interface to act like it.
Another problem is while I could use the newer Promise version, Promises themselves raise Exceptions. Errors are values in Functional Programming, not side effects that break your stuff.
I can fix both problems fixing it in JavaScript by providing a nicer function that either returns a success with the contents or nothing. This maps to an Option, also called a Maybe in other languages. While there are a multitude of reasons reading a file can fail, I don’t care, it’s just for caching in an AWS Lambda. Either give me a string or don’t.
export const safeReadFile = filename =>
new Promise(
resolve =>
readFile(
filename,
(error, data) =>
error
? resolve(undefined)
: resolve(safeParseData(data))
)
)
.catch(
_ =>
Promise.resolve(undefined)
)
Code language: JavaScript (javascript)Wrapped in a Promise, she’ll automatically get free try/catch in case I miss something. In that case, our catch ensures any unknowns, such as permission to read file errors are handled safely. Second, if it fails, I resolve the Promise successfully with an undefined
const safeParseData = data => {
try {
const string = data.toString()
return string
} catch(error) {
return undefined
}
}Code language: JavaScript (javascript)Finally, while we may be able to read a Buffer successfully from the file, there is no guarantee toString() will be successful, so we safely handle that as well. I save this as safeReadFile.js.
What does ReScript get? A much easier module function binding:
@module("./safeReadFile") external safeReadFile string => Js.Optional.t<string> = "safeReadFile"Code language: JavaScript (javascript)You can read that as “The safeReadFile function ‘safeReadFile.mjs’ takes in a string, and returns either a string or nothing”. Now within ReScript, I can safely use her without worrying about edge cases, typing callbacks, ensuring this still works, no worries about null vs undefined… all those problems go away… using JavaScript.
switch safeReadFile("cache.txt") {
| None => "No cache, fetch data."
| Some(data) => data
}Code language: JavaScript (javascript)2 Type Libraries
I didn’t really grok 80% of this till this weekend, but ReScript types both ReScript and JavaScript. It seems strange as ReScript compiles too JavaScript, but because of integration, you’ll have JavaScript call ReScript and ReScript call JavaScript. While in the end “it’s all JavaScript”, there are opportunities for type safety before you get there.
For example, in TypeScript and Elm, there are Types, and in TypeScript they also have interfaces. In Elm, they’re sound and are eventually compiled to Objects. If you want to talk to JavaScript, or have JavaScript talk to you through ports, they’re still typed; no dynamic or “any” here. In TypeScript, you have a lot more flexibility, which can help code faster, but risks runtime errors if you’re types aren’t handling all edge cases. ReScript doesn’t do that. It makes a clear distinction, in types, between your ReScript Object (called a Record) and a JavaScript Object… then provides types for both.
That really made my head fuzzy until I realized why. While your Person may be all nice and typed, the Person you get from JavaScript may not be; who knows what it has… it could even be null instead of undefined. Elm would blow up if you didn’t use a Maybe. ReScript not only handles that, but gives you the tools to type with that… and sometimes blows up like Elm “because JavaScript”. I’m still learning, but this mental model wasn’t really explained in the documentation; I thought it was just the confusing Bucklescript vs. Reason branding thing, but it’s actually a really powerful feature. While ReScript is soundly typed, this gives you flexibility in_how soundly typed you want to make it. This is helpful when you’re learning on what is the best way to integrate with various JavaScript libraries and code.
Lesson #3: You have some flexibility in typing JavaScript separately, which can help in ensuring you don’t have to refactor or create any new JavaScript code, you can just type with what you’re given, or what you intend to send over when you’re still figuring out your data.
Options vs Nullable Options
I don’t use null, but a lot of developers still do, sometimes to differentiate between undefined. An example of this is in the popular JSON Web Token library. When decoding a JWT, she’ll return an Object, null, or raise an Exception. What you really want is either it decodes or it doesn’t. While the error may be helpful and possibly provide insight, null does not. Most of the time you’d want to explore the Exception, but in our case, we’re just verifying of it works or not in a library. Thus an Option is good enough. However, now you have 4 things instead of 2 things. What you want is Object or undefined, but you now also have null and Exception. Again, you can dive down the type rabbit hole, which can be fun to learn, OR just fix the API to be easier to work with.
const decode = token => {
try {
const result = jwt.decode(token, { complete: true } )
return result
} catch {
return undefined
}
}Code language: JavaScript (javascript)This gets us partially the way there: she’ll now return undefined, null, and an Object. ReScript provides a special type, called Nullable, that handles this exact scenario, since it’s extremely common in JavaScript for undefined and null to basically mean Nothing, or in our case the Option None.
@module("./safeJWT") external decode string => Js.Nullable.t<string> = "decode"Code language: JavaScript (javascript)JavaScript Calling a ReScript Compiled Library
I finally re-created my first ReScript library, went to call it, and got an exception 😞. However, I then got excited, and thought, “Ok, cool, how could this happen in a soundly typed language?”. It turns out, JavaScript was passing in the wrong parameters. In my old API, I exposed a function that took a single Object with optional values, and passed those to the private one:
const validate = options =>
_validate(
options?.url,
options?.key,
options?.useCache ?? true
)Code language: JavaScript (javascript)Screwing any of these up would lead to an Error, but all Exceptions were handled as a single catch, and most were known, so you’d actually get reasonably good errors explaining why.
However, there is a strategy I tried once using Folktale’s Validation API to provide more meaningful type errors before you go down that path of throwing bad data in your Promise chains and seeing what happens. While a lot of work, this helped the user because they knew immediately what they did wrong, and the error messages were handcrafted to help them. Each key on the options is validated, and you can get a list of failures, or nothing and you know your data is good. Now, this is at runtime.
const getOr = (defaultValue, prop, object) =>
(object ?? {})?.[prop] ?? defaultValue
const legitURL = options => {
const url = getOr("???", "url", options)
if(url === "???") {
return Failure(["You did not provide an options.url. It either needs to be QA: http://qa.server or Production: http://prod.server."])
}
if(url.indexOf("http://") < 0) {
return Failure([`Your options.url does not appear to be a validate HTTP url. You sent: ${url}`])
}
return Success(url)
}Code language: JavaScript (javascript)While I cannot easily type the URL’s contents for validation (this is why Functional Programmers think String is untyped), I can type the inputs as Options with defaults, such as key and useCache, then pattern match on those confidently. For the ones that have no defaults, like url, I can type these as Result and immediately convert to an Exception for the outside JavaScript world. She’d be typed as such:
type config = {
url: option<string>,
key: option<string>,
useCache: option<string>
}Code language: HTML, XML (xml)Then a bunch of code to handle all the None‘s that arise. In the Elm world, you’re just uber careful about what you accept through ports from JavaScript, but in ReScript, my primary use case is libraries which are consumed in non-typed ways. So it’s not a drastic change, just a gotcha I didn’t think about until I tested my own library in JavaScript.
Lesson #4: While ReScript is typed, at runtime there are no compiler errors, so it’s still nice to provide helpful errors to those who are using your library in JavaScript.
Conclusions
My world changed for the better last weekend. I had been struggling for awhile to be productive with ReScript and I finally produced a working library. I feel confident I could now do it without an existing domain in place, and could create something new, or just integrate with a variety of other JavaScript libraries confidently.
With that new confidence comes a feeling that I finally have a server-side tool to compliment Elm on the client-side. Well, until Darklang or Roc give me reason to move.
Most importantly, though, although I’m not an expert in all the types and syntax and API’s, I feel I can confidently teach others so they can be productive, and in turn teach me. That’s super empowering. For those of you who read my In Search of a Typed Functional Programming Language, you can see why.
The compiler errors aren’t as nice as Elm, but that’s ok, I’m slowly learning. Given I already know JavaScript, I feel I can easily compensate for either a lack of ReScript type knowledge, or just a hard to work with library that I want to be more strongly, and hopefully soundly, typed. Finally, I can still use my existing data type validation skills to provide helpful errors / return values to users consuming my libraries. That and even large code + associated unit tests compile soooo fast compared to TypeScript, it’s crazy. Excited to try this on some larger projects and see how she scales.
That, and she already integrates with all my existing Node.js infrastructure, CI/CD tooling, and AWS Serverless integration.
My only cons to ReScript that could change as I learn more is around the sound typing, side effects, and pipeline support.
While the sound typing is one of my original draws aside from the fast compilation, it’s really easy to screw it up, and it’s not ReScript’s fault, it’s JavaScript. You really have to have a Functional Programming mindset to ensure your JavaScript is written in such a way to make sure the sound typing in ReScript holds, or be extremely careful with JavaScript Objects that aren’t quite Records in ReScript. It’s an interesting take, much like F#, where it’s like “Look, we’re sound, but we’re also pragmatic, we work with code that may have type problems or exceptions, but if you have a functional mindset, you’re probably ok”. I like that.
The only really disappointing thing, but easy way to mitigate, is the side effects. ReScript is a lot like TypeScript i.e. types on top. So there is no runtime beyond some helper libraries you can include or the compiler includes. This means that despite types, you still have side effects, and you have to deal with them and the types can only help so much. With Elm, a whole slew of problems go away and your code becomes much cleaner. For me, I’ve typically used Dependency Injection of mitigating them in JavaScript, but now that I’ve got types, I wonder if there is a more effect style way of doing things. For now, using Promise chains with pattern matching gives me a pretty close to Elm experience without the race conditions I occasionally run into in Elm.
The biggest brain twist is data-first. I’m still learning pipelines in ReScript, but I still architect specifically for data-last. ReScript is pretty clear it’s a data-first language. As someone who has been doing Functional Programming for a few years now, this has been super hard re-learn how to do this super common thing. Thankfully the pipe-placeholders help a lot. Elm has both so I’m starting to wonder if my Elm code will be affected by being forced to be data-first in ReScript?
Ultimately, I’m just so happy to have strongly typed functional code WITHOUT having to add types everywhere. I get the benefits of TypeScript and more without all the work or slow compilation speeds.